《将 Transformer 架构应用于图像识别任务》
Submitted on 22 Oct 2020 (v1), last revised 3 Jun 2021 (this version, v2),ICLR 2021
简介
这篇论文主要介绍ICLR 2021上的、一个基于Transformer模型应用于处理图像识别任务的ViT模型,证明了纯 Transformer 模型直接处理图像块序列在图像分类任务中能有出色表现。
0 摘要
翻译
尽管 Transformer 架构已成为自然语言处理任务的事实标准,但其在计算机视觉领域的应用仍十分有限。在视觉任务中,注意力机制通常要么与卷积网络结合使用,要么用于替换卷积网络的某些组件,同时保留卷积网络的整体结构。
本文表明,这种对卷积神经网络(CNNs)的依赖并非必需 ——将纯 Transformer 直接应用于图像块序列,在图像分类任务中就能表现出色。当在大量数据上进行预训练,并迁移到多个中型或小型图像识别基准任务(如 ImageNet、CIFAR-100、VTAB 等)时,Vision Transformer(ViT)与最先进的卷积网络相比,能取得优异的结果,同时训练所需的计算资源显著减少。
动机:Transformer广泛应用于自然语言处理,但在计算机视觉领域的应用仍十分有限;
本文的贡献、完成的任务:证明计算机视觉任务对CNNs的依赖不是必要的,将纯 Transformer 直接应用于图像块序列,在图像分类任务中就能表现出色。本文的ViT(Vision Transformer)模型与最先进的CNN相比,得到了更加优异的结果,并且减少了训练所需要的计算资源;
1 引言
翻译
基于自注意力机制的架构,尤其是 Transformer(Vaswani 等人,2017),已成为自然语言处理(NLP)任务的首选模型。其主流方法是在大型文本语料库上预训练,然后在较小的特定任务数据集上微调(Devlin 等人,1989)。得益于 Transformer 的计算效率和可扩展性,训练规模空前的模型成为可能,参数数量已超过 1000 亿(Brown 等人,2020;Lepikhin 等人,2020)。随着模型和数据集的不断扩大,性能尚未显现出饱和的迹象。
然而,在计算机视觉领域,卷积架构仍然占据主导地位(LeCun 等人,1989;Krizhevsky 等人,2012;He 等人,2016)。受 NLP 领域成功案例的启发,多项研究尝试将类 CNN 架构与自注意力机制结合(Wang 等人,2018;Carion 等人,2020),也有部分研究完全替换卷积操作(Ramachandran 等人,2019;Wang 等人,2020a)。尽管后者在理论上具有效率优势,但由于使用了专门的注意力模式,尚未能在现代硬件加速器上有效扩展。因此,在大规模图像识别中,经典的类 ResNet 架构仍是当前的最优选择(Mahajan 等人,2018;Xie 等人,2020;Kolesnikov 等人,2020)。
受 Transformer 在 NLP 领域规模化成功的启发,我们尝试将标准 Transformer 直接应用于图像,且尽可能少地进行修改。具体而言,我们将图像分割为多个补丁(patches),并将这些补丁的线性嵌入序列作为 Transformer 的输入。图像补丁的处理方式与 NLP 应用中的标记(tokens,如单词)完全相同。我们以有监督的方式在图像分类任务上训练该模型。
当在中等规模数据集(如 ImageNet)上训练且未使用强正则化时,这些模型的精度表现平平,比同等规模的 ResNet 低几个百分点。这一结果看似令人沮丧,但其实在意料之中:Transformer 缺乏 CNN 固有的一些归纳偏置(如平移等变性和局部性),因此在训练数据不足时泛化能力较差。
然而,若在更大的数据集(1400 万 – 3 亿张图像)上训练,情况会有所改观。我们发现,大规模训练的效果优于归纳偏置。当在足够大的规模上预训练后,我们提出的 Vision Transformer(ViT)在迁移到数据量较少的任务时能取得优异结果。在公开的 ImageNet-21k 数据集或内部的 JFT-300M 数据集上预训练后,ViT 在多个图像识别基准测试中接近或超过了当前最优水平。具体而言,最优模型在 ImageNet 上达到 88.55% 的准确率,在 ImageNet-ReaL 上达到 90.72%,在 CIFAR-100 上达到 94.55%,在包含 19 个任务的 VTAB 套件上达到 77.63%。
1、Transformer在计算效率、可扩展性方面具有优势;得益于Transformer的优势,随着模型和数据集的不断扩大,性能也变得越来越好;
2、本文将Transformer应用于图像方的方法:将图像分割为多个patches(补丁),并将这些补丁的线性嵌入序列作为Transformer的输入,图像补丁的处理方式与自然语言处理应用中的tokens(单词等)完全相同;以有监督的方式(指的是基于标签的图像分类训练模式,每个图片都有real target)在图像分类任务上训练ViT模型;
但是这种方法在处理规模不大的数据集中,会因数据不足而导致模型泛化能力较差;
3、本文成果:在ImageNet上取得88.55%准确率,ImageNet-ReaL 上达到 90.72%,在 CIFAR-100 上达到 94.55%,在包含 19 个任务的 VTAB 套件上达到 77.63%;
2 相关工作
翻译
Transformer 由 Vaswani 等人(2017)提出,最初用于机器翻译任务,此后成为众多自然语言处理(NLP)任务的最先进方法。大型基于 Transformer 的模型通常在大型语料库上预训练,再针对具体任务进行微调:BERT(Devlin 等人,2019)采用去噪自监督预训练任务,而 GPT 系列则以语言建模作为预训练任务(Radford 等人,2018;2019;Brown 等人,2020)。
若将自注意力机制直接应用于图像,会要求每个像素与其他所有像素进行注意力交互。由于计算成本与像素数量成二次方关系,这种方式无法扩展到实际的输入尺寸。因此,过去为了在图像处理中应用 Transformer,研究人员尝试了多种近似方法。Parmar 等人(2018)仅在每个查询像素的局部邻域内应用自注意力,而非全局范围内。此类局部多头点积自注意力块可完全替代卷积操作(Hu 等人,2019;Ramachandran 等人,2019;Zhao 等人,2020)。另一类研究中,稀疏 Transformer(Child 等人,2019)采用可扩展的全局自注意力近似方法,以适用于图像。另一种扩展注意力的方式是在不同大小的块上应用注意力(Weissenborn 等人,2019),极端情况下仅沿单个轴应用(Ho 等人,2019;Wang 等人,2020a)。这些专门设计的注意力架构在计算机视觉任务上展现出良好前景,但需要复杂的工程实现才能在硬件加速器上高效运行。
与我们的工作最相关的是 Cordonnier 等人(2020)的模型,该模型从输入图像中提取 2×2 大小的补丁,并在其之上应用完整的自注意力。该模型与 ViT 非常相似,但我们的工作进一步证明,大规模预训练能使 vanilla Transformer(基础 Transformer)与最先进的 CNN 相竞争(甚至更优)。此外,Cordonnier 等人(2020)使用 2×2 像素的小补丁尺寸,这使得模型仅适用于低分辨率图像,而我们的模型也能处理中等分辨率图像。
将卷积神经网络(CNN)与自注意力机制相结合的研究也备受关注,例如通过增强特征图用于图像分类(Bello 等人,2019),或使用自注意力进一步处理 CNN 的输出,如用于目标检测(Hu 等人,2018;Carion 等人,2020)、视频处理(Wang 等人,2018;Sun 等人,2019)、图像分类(Wu 等人,2020)、无监督目标发现(Locatello 等人,2020),或统一的文本 – 视觉任务(Chen 等人,2020c;Lu 等人,2019;Li 等人,2019)。
另一项近期相关的模型是 image GPT(iGPT)(Chen 等人,2020a),它在降低图像分辨率和压缩色彩空间后,将 Transformer 应用于图像像素。该模型以无监督方式作为生成模型训练,其得到的特征表示可通过微调或线性探测用于分类任务,在 ImageNet 上最高达到 72% 的准确率。
我们的工作加入了越来越多探索超大规模图像识别的研究行列,这些研究使用的数据集规模超过标准的 ImageNet。利用额外数据源有助于在标准基准测试上取得最先进结果(Mahajan 等人,2018;Touvron 等人,2019;Xie 等人,2020)。此外,Sun 等人(2017)研究了 CNN 性能如何随数据集大小扩展,Kolesnikov 等人(2020)和 Djolonga 等人(2020)则实证探索了从 ImageNet-21k 和 JFT-300M 等大规模数据集迁移学习的 CNN 模型。我们同样聚焦于这两个数据集,但训练的是 Transformer 而非先前工作中基于 ResNet 的模型。
术语说明
Transformer: 用于机器翻译的方法,被广泛用于NLP领域
BERT: 使用去噪自我监督的训练前任务
局部多头点积自我注意块: 只在每个查询像素的局部社区中应用自注意力,可以完全取代卷积
稀疏Transformer: 采用了对全局自关注的可扩展近似,以便适用于图像
在不同大小的块中应用: 在极端情况下,只沿着个别轴线应用
iGPT: 无监督的方式,在降低图像分辨率和色彩空间后将Transformers应用于图像像素
3 方法
翻译
在模型设计中,我们尽可能贴近原始 Transformer(Vaswani 等人,2017)的结构。这种刻意简化的设计有一个优势:可扩展的自然语言处理(NLP)Transformer 架构及其高效实现几乎可以直接复用。
3.1 Vision Transformer(ViT)
①
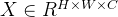
②
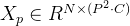
③
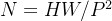
④
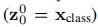
⑤
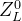
翻译
标准 Transformer 的输入是一维标记嵌入序列(sequence of token embeddings)。 为了处理 2D 图像,我们将图像① reshape为一系列展平的 2D patches② ,其中 (H, W ) 是原始图像的分辨率,C 是 通道数,(P, P ) 是每个图像patch的分辨率,③是patches数目,它也用作 Transformer 的有效输入序列长度。 Transformer 在其所有层中使用恒定的潜在向量大小 D,因此我们将patches展平并使用可训练的线性投影映射到 D 维(方程 1)。 我们将此投影的输出称为patch embeddings。
与 BERT 的 [class] token类似,我们在嵌入patches序列 (sequence of embedded patches④) 中添加了一个可学习的embeddings,其在 Transformer encoder (⑤) 的输出端的状态用作图像表示 y(方程 4) . 在预训练和微调期间,分类头都连接到。分类头由带有一个隐藏层的 MLP 在预训练时实现,在微调时由单个线性层实现。
position embeddings被添加到patch embeddings中以保留位置信息。 我们使用标准的可学习一维position embeddings,因为我们没有观察到使用更高级的二维感知position embeddings(附录 D.4)带来的显着性能提升。 得到的embeddings向量序列作为encoder的输入。
Transformer encoder(Vaswani 等人,2017 年)由multi-head self-attention(MSA,参见附录 A)和 MLP blocks(方程 2、3)的交替层组成。 在每个块之前应用layerNorm (LN),在每个块之后应用残差连接(Wang 等人,2019 年;Baevski 和 Auli,2019 年)。
归纳偏置:我们注意到 Vision Transformer 比 CNN 具有更少的特定于图像的归纳偏差。 在 CNN 中,局部性、二维邻域结构和平移等效性被传递到整个模型的每一层中。 在 ViT 中,只有 MLP 层是局部和平移不变的,而self-attention层是全局的。 二维邻域结构的使用非常谨慎:在模型开始时通过将图像切割成patches,并在微调时调整不同分辨率图像的position embeddings(如下所述)。 除此之外,初始化时的position embeddings不携带有关patches的 2D 位置的信息,patches之间的所有空间关系都必须从头开始学习。
混合架构:作为原始图像patches的替代方案,输入序列可以由 CNN 的feature maps形成(LeCun 等,1989)。 在这个混合模型中,patch embedding投影 E(方程 1)应用于从 CNN featuremap中提取的patches。 作为一种特殊情况,patch 的空间大小可以为 1×1,这意味着输入序列是通过简单地将feature maps的空间维度展平并投影到 Transformer 维度来获得的。 如上所述添加了分类输入embedding和position embeddings。
ViT模型结构
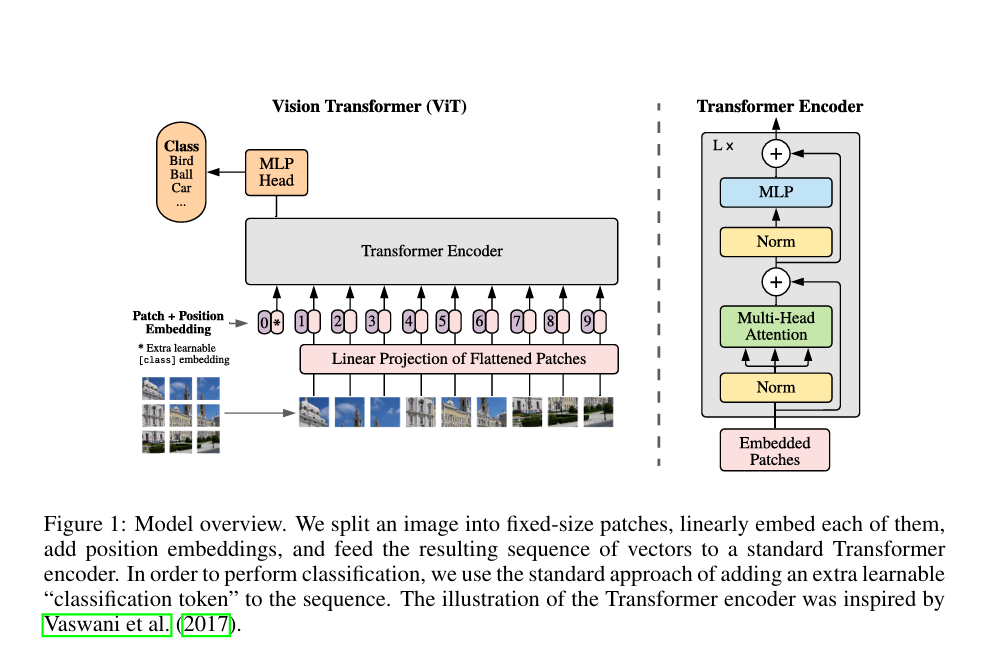
第一部分-输入
将图像分割为多个patches,并将这些补丁的线性嵌入序列作为Transformer的输入
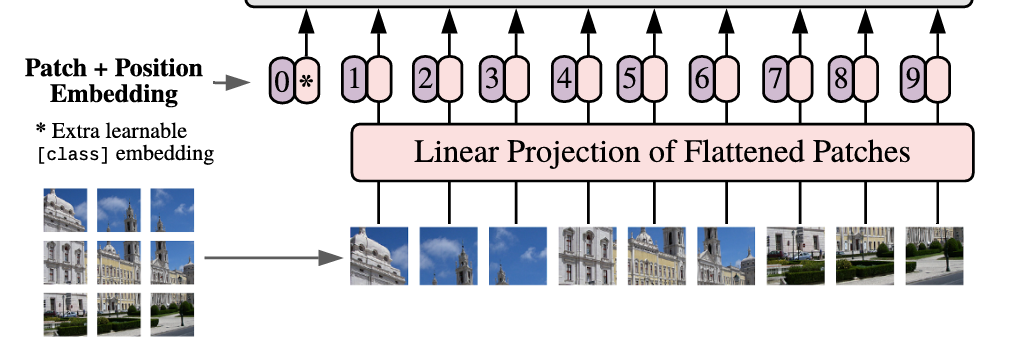
首先输入一张图片,将这个图片分为了9个patch,然后将每个patch重组成一个向量,得到Flatten patch;
如果图片是H×W×C维的,就用P×P大小的patch去分割图片可以得到N个patch,那么每个patch的大小就是P×P×C,将N个patch 重组后的向量concat在一起就得到了一个N×P×P×C的二维矩阵,相当于NLP中输入Transformer的词向量;
Linear Projection of Flatten Patches,作用是将图像补丁转换为 Transformer 可处理的嵌入向量;
第二部分-Position Embedding

之前学习Transformer可以知道,Transformer模型本身是不知道每个“词”的位置信息的,因此就需要Position Embedding将位置信息加到模型中;
如上图所示,编号有0-9的紫色框表示各个位置的position embedding,而紫色框旁边的粉色框则是经过linear projection之后的flattened patch向量(就相当于NLP中词向量加上位置编码);
文中采用将position embedding(即图中紫色框)和patch embedding(即图中粉色框)相加的方式结合position信息。
第三部分-learnable embedding
将 patch 输入一个 Linear Projection of Flattened Patches 这个 Embedding 层,就会得到一个个向量,通常就称作 tokens。tokens包含position信息以及图像信息。
紧接着在一系列 token 的前面加上加上一个新的 token,叫做class token,也就是上图带星号的粉色框(即0号紫色框右边的那个),注意这个不是通过某个patch产生的。其作用类似于BERT中的[class] token。在BERT中,[class] token经过encoder后对应的结果作为整个句子的表示;class token也是其他所有token做全局平均池化,效果一样;
它是模型训练过程中 通过反向传播不断更新参数 的嵌入,会根据训练数据(图像及对应标签)学习到对分类任务更有效的表示,所以属于 “learnable embedding” ;
第四部分-Transformer Encoder
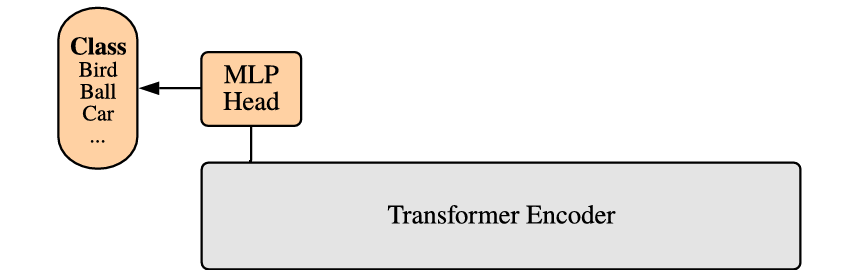
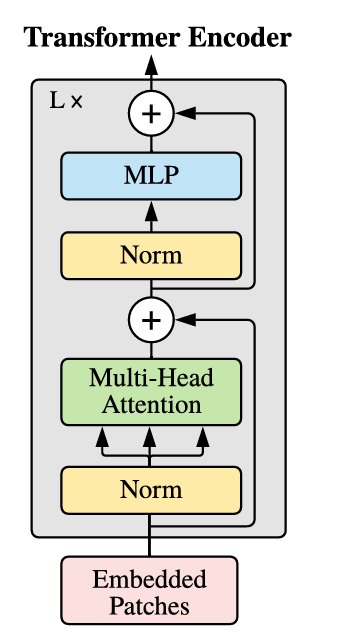
将前面处理后的内容输入到Transformer Encoder中,将 block (Transformer Encoder内部的核心重复单元)重复堆叠 L 次,整个模型也就包括 L 个 Transformer。Transformer Encoder结构和NLP中Transformer结构基本上相同,class embedding 对应的输出经过 MLP Head 进行类别判断。
3.2 微调与更高分辨率
翻译
通常,我们会在大型数据集上对ViT进行预训练,并对(较小的)下游任务进行微调。为此,我们去掉了预先训练好的预测头,并附加了一个零初始化的D×K前馈层,其中K是下游类的数量。与训练前相比,以更高的分辨率进行微调往往有益的(Touvron等人,2019;科列斯尼科夫等人,2020年)。当输入更高分辨率的图像时,我们保持patch大小不变,这导致更大的有效序列长度。视觉转换器可以处理任意的序列长度(直到内存限制),然而,预先训练的Position embeding可能不再有意义。因此,我们根据预先训练好的位置embeding在原始图像中的位置,进行二维插值。请注意,这种分辨率调整和patch提取是将图像二维结构的感应偏差手动注入视觉transformer的唯一点。
存在的问题:在下游任务的图像的分辨率会变大(导致图像的长和宽会增加),本文保持Patch大小不变,导致最后得到的Patch个数增加,这样的话这里的Patch与Position embedding处理得到的Patch个数不同,不能保证其中的位置语义信息还有左右,因此可能导致Position embedding失去意义;
解决方法:根据预先训练好的位置embeding在原始图像中的位置,进行二维插值,基于原图中的位置信息,将预训练中的 position embedding的数量经过插值变成增加之后的。这样在得到对应数目的position embedding的同时也保证了position embedding的语义信息;
4 实验
翻译
我们评估了 ResNet、视觉 Transformer(ViT)以及混合模型的表征学习能力。为了探究每个模型对数据的需求,我们在不同规模的数据集上进行预训练,并在多个基准任务上展开评估。从预训练的计算成本来看,ViT 表现十分优异 —— 它能以更低的预训练成本,在大多数识别基准任务上达到最先进水平。最后,我们开展了一项关于自监督学习的小型实验,结果表明自监督 ViT 在未来具有良好的应用前景。
4.1 实验设置
翻译
Datasets. 探索模型的可伸缩性,我们使用ILSVRC-2012图像数据集1k类和1.3M图像(我们称之为“ImageNet如下),其超集ImageNet-21k 21k类和14M图像(邓等,2009),和JFT(sun等,2017)18k类和303高分辨率图像。我们将训练前的数据集w.r.t.在Kolesnikov等人(2020年)之后的下游任务的测试集。我们将在这些数据集上训练的模型转移到几个基准任务中:原始验证标签和清理后的ReaL标签(Beyer等人,2020年),CIFAR-10/100(克里热夫斯基,2009年),Oxford-IIIT Pets (Parkhi et al., 2012), and Oxford Flowers-102 (Nilsback & Zisserman, 2008)。对于这些数据集,预处理遵循Kolesnikov等人(2020年)。
我们还评估了包含19个任务的VTAB分类套件(Zhai等人,2019b)。VTAB为每个任务使用1 000 个训练示例。这些任务被分为三组:Natural – tasks ,如上述任务,宠物,CIFAR等。专业的医疗和卫星图像,以及结构化的任务,需要几何理解,如局部化。
Model Variants. 我们基于BERT中使用的ViT配置(Devlinetal.,2019),如表1所示。“base”和“Large”模型直接采用了BERT,我们添加了更大的“huge”模型。在接下来的内容中,我们使用简短的符号来表示模型大小和输入patch大小:例如,ViT-L/16表示具有16×16输入patch大小的“Large”变体。请注意,transformer的序列长度与patch大小的平方成反比,因此具有较小patch大小的模型的计算成本更高。
对于基线cnn,我们使用ResNet(He等人,2016年),但将批处理归一化层(Wu&He)替换为组归一化(Ioffe&ϟ,2015年),并使用标准化卷积(Qiao等人,2019年)。这些修改改善了转移(科列斯nikov等人,2020年),我们将修改后的模型表示为“ResNet(BiT)”。对于混合体,我们将中间特征映射输入具有一个“像素”的patch大小的ViT。为了实验不同的序列长度,我们要么(i)取常规ResNet50的第4阶段的输出,或者(ii)删除第4阶段,在第3阶段中放置相同数量的层(保持层的总数),并取这个扩展阶段3的输出。选项(ii)导致一个4倍长的序列长度,和一个更昂贵的ViT模型。
Training & Fine-tuning. 我们使用Adam(Kingma&Ba,2015)和β1=0.9,β2=0.999,批处理大小为4096,并应用0.1的高weight decay,我们发现这对所有模型的转移都很有用(附录D.1表明,与常见的做法相比,Adam对resnet的设置效果比SGD稍好)。我们使用线性学习率预热和衰减,见附录B.1的细节。对于微调,我们使用具有动量的SGD,批处理大小为512,对于所有模型,请参见附录B.1.1。对于表2中的ImageNet结果,我们以更高的分辨率进行了微调:ViT-L/16为512,ViT-H/14为518,同时还使用了Polyak&朱迪茨基(1992),平均系数为0.9999(拉曼钱德兰等人,2019;Wang等人,2020b)。
Metrics. 我们通过few-shot或微调精度来报告下游数据集的结果。微调精度可以在对各自的数据集进行微调后捕获每个模型的性能。few-shot精度是通过求解一个正则化最小二乘回归问题来获得的,该问题将训练图像子集的(冻结)表示映射到{−1,1}^K个目标矢量。这个公式使我们能够恢复封闭形式的精确解。虽然我们主要关注微调性能,但我们有时会使用线性的few-shot精度来进行快速的动态评估,因为微调成本太高。
预训练数据集:
ILSVRC-2012 ImageNet(含 1k 类别、130 万张图像,下文简称 ImageNet);
其超集 ImageNet-21k(含 21k 类别、1400 万张图像,Deng 等人,2009);
JFT 数据集(含 18k 类别、3.03 亿张高分辨率图像,Sun 等人,2017)。
模型评估数据集:
ImageNet(原始验证标签及清理后的 ReaL 标签,Beyer 等人,2020);
CIFAR-10/100(Krizhevsky,2009);
Oxford-IIIT Pets(Parkhi 等人,2012);
Oxford Flowers-102(Nilsback & Zisserman,2008);
模型:
论文共设计了Base、Large和Huge三款不同大小的ViT模型,分别表示基础模型、大模型和超大模型,三款模型的各参数如下表所示:
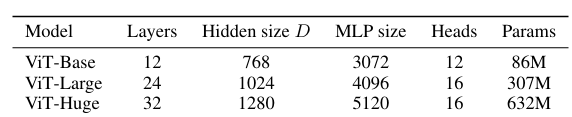
基于BERT中使用的ViT配置(Devlinetal.,2019),“base”和“Large”模型直接采用了BERT,又设计一个huge超大:
训练、微调:
Adam训练,训练批次4096;
SGD微调,批次512
衡量标准:
少数镜头或微调精度;
4.2 与最先进模型的对比
翻译
我们首先将最大规模的模型 ——ViT-H/14 和 ViT-L/16,与文献中最先进的卷积神经网络(CNNs)进行对比。对比对象包括两个:一是 “Big Transfer(BiT)”(Kolesnikov 等人,2020),它基于大型 ResNet 进行有监督迁移学习;二是 “Noisy Student”(Xie 等人,2020),这是一个大型 EfficientNet,通过半监督学习在 ImageNet 和去除标签的 JFT-300M 数据集上训练。目前,Noisy Student 是 ImageNet 上的最先进模型,而 BiT-L 则在本文报告的其他数据集上表现最优。所有模型均在 TPUv3 硬件上训练,我们同时报告了每个模型预训练所需的 TPUv3 核心天数(即训练所用的 TPUv3 核心数(每芯片 2 个核心)乘以训练天数)。
表 2 展示了对比结果。在 JFT-300M 数据集上预训练的较小模型 ViT-L/16,在所有任务上的表现均优于同样在该数据集上预训练的 BiT-L,且训练所需的计算资源显著更少。更大的模型 ViT-H/14 进一步提升了性能,尤其在更具挑战性的数据集(ImageNet、CIFAR-100 和 VTAB 套件)上表现突出。有趣的是,该模型的预训练计算量仍显著低于此前的最先进模型。不过需要注意的是,预训练效率不仅受架构选择影响,还与其他参数(如训练调度、优化器、权重衰减等)相关。我们将在 4.4 节中对不同架构的 “性能 – 计算量” 关系进行对照研究。最后,在公开的 ImageNet-21k 数据集上预训练的 ViT-L/16 模型在大多数数据集上也表现良好,且预训练资源更少:使用标准的 8 核云 TPUv3,大约 30 天即可完成训练。
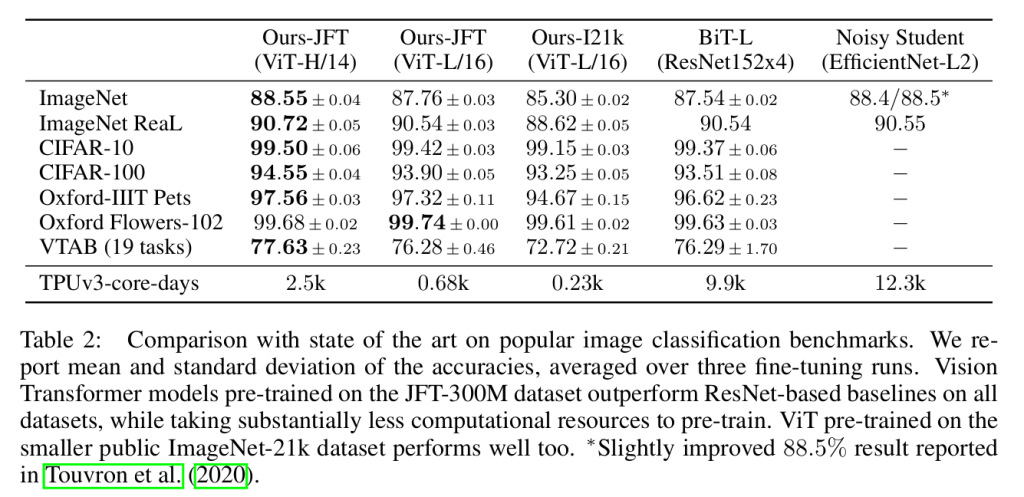
表2是将最大的模型ViT-H/14和ViT-L/16,与BiT和Noisy Student进行比较;
结论:我们的模型计算量要小得多,并且精度更高
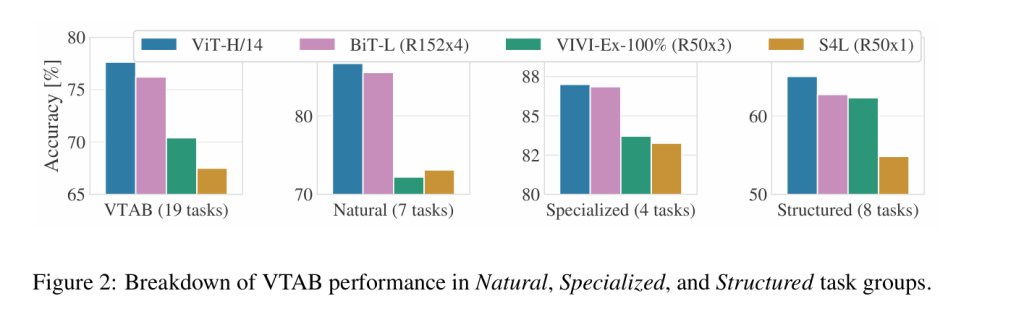
图2将 VTAB 任务分解为各自的组,并在此基准测试中与之前的 SOTA 方法进行比较
结论:ViT和BiT类似,并高于别的方法
VTAB任务即视觉任务适应性基准(Visual Task Adaptation Benchmark)任务,它是Google AI Research提出的一个用于评估视觉模型表示能力的基准测试,旨在衡量模型在未知任务和有限数据上的性能,推动通用视觉算法的发展;
VTAB任务相关介绍
任务构成:VTAB 包含 19 个评估任务,跨越多个领域,分为自然(Natural)、专业(Specialized)和结构化(Structured)三组。自然图像任务包括通过标准相机捕获的自然界图像,代表通用对象、细粒度类或抽象概念等;专门任务利用专业设备捕获的图像,例如医学图像或遥感图像;结构化任务通常源自旨在理解图像之间特定变化的人工环境,如预测到 3D 场景中某个对象的距离、计数对象或检测方向等。
评估方式:该基准测试期望将经过预训练的模型作为输入,给定模型针对不同的视觉任务经过独立微调,来解决上述任务。为了评估对数据有限的新任务的算法概括能力,每个任务仅使用 1000 个示例来评估性能,所有任务的平均准确度用于衡量模型的性能。
任务目的:VTAB 旨在为视觉表示学习提供一个统一的评估标准。通过这个基准,可以帮助研究人员区分哪些模型适用于通用视觉任务,哪些不适用,从而为将来的视觉评估方向提供指引,促进通用和实用的视觉算法的发展。
4.3 预训练数据需求
翻译
Vision Transformer 在大规模 JFT-300M 数据集上预训练时表现优异。由于其视觉相关的归纳偏置比 ResNet 更少,那么数据集大小对其影响有多关键?我们通过两组实验进行探究。
第一组实验中,我们在规模递增的数据集(ImageNet、ImageNet-21k、JFT-300M)上预训练 ViT 模型。为提升在较小数据集上的性能,我们优化了三个基础正则化参数 —— 权重衰减、dropout 和标签平滑。图 3 展示了在 ImageNet 上微调后的结果(其他数据集的结果见表 5)。在最小的数据集 ImageNet 上预训练时,尽管使用了(适度的)正则化,ViT-Large 模型的性能仍低于 ViT-Base 模型;在 ImageNet-21k 上预训练时,两者性能接近;只有在 JFT-300M 上预训练时,更大模型的优势才完全显现。图 3 还展示了不同规模 BiT 模型的性能范围:BiT 卷积神经网络在 ImageNet 上的表现优于 ViT,但随着数据集规模增大,ViT 实现了反超。
第二组实验中,我们在 JFT-300M 的随机子集(900 万、3000 万、9000 万张图像)以及完整数据集上训练模型。所有设置均使用相同超参数,未对小子集额外施加正则化,以此评估模型的内在属性而非正则化的影响。不过,我们采用了早停策略,并报告训练过程中达到的最佳验证准确率。为节省计算资源,我们使用少样本线性准确率而非完整微调准确率作为评估指标,结果如图 4 所示。在较小数据集上,与计算成本相当的 ResNet 相比,Vision Transformer 更容易过拟合。例如,ViT-B/32 的训练速度略快于 ResNet50,在 900 万图像子集上表现差很多,但在 9000 万以上子集上表现更优;ResNet152x2 与 ViT-L/16 的对比也呈现相同规律。这一结果印证了一个直觉:卷积归纳偏置在较小数据集上更有用,但对于更大的数据集,直接从数据中学习相关模式就足够了,甚至更有利。
总体而言,ImageNet 上的少样本结果(图 4)以及 VTAB 上的低数据量结果(表 2),表明 ViT 在极低数据量迁移场景中具有潜力。对 ViT 少样本特性的进一步分析,将是未来令人期待的研究方向。
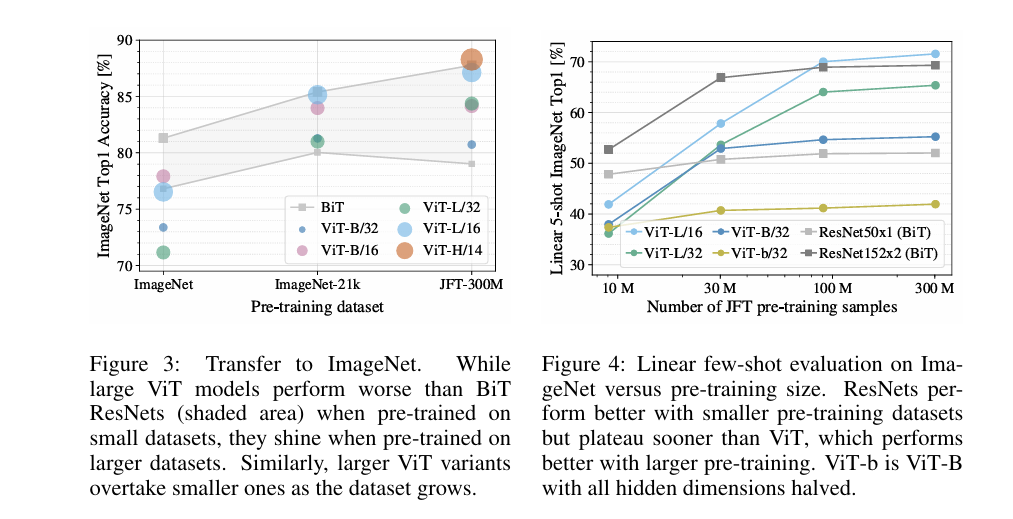
图3展示了模型在 ImageNet 数据集上的性能;
图4展示了在 JFT300M 数据集的随机子集以及完整数据集上进行了模型训练的结果;
结论:卷积归纳偏置对于规模较小的数据集较为有用,但对于较大的数据集而言,学习相关模式就足够了,甚至更加有效。
4.4 模型扩展研究
翻译
我们通过对不同模型进行了受控缩放研究评估 JFT-300M 的迁移性能。 在这种情况下,数据大小不会限制模型的性能,我们评估每个模型的性能与预训练成本。 模型集包括:7个ResNets,R50x1、R50x2、R101x1、R152x1、R152x2,预训练了7个epochs,加上预训练了14个epochs的R152x2和R200x3; 6个Vision Transformers,ViT-B/32、B/16、L/32、L/16,预训练7个epochs,加上L/16和H/14预训练14个epochs; 和 5 个混合,R50+ViT B/32、B/16、L/32、L/16 预训练了 7 个 epoch,加上 R50+ViT-L/16 预训练了 14 个 epoch(对于混合,最后的数字 模型名称不代表patch大小,而是代表 ResNet 主干中的总下采样率)。
图 5 包含迁移性能与总预训练计算(有关计算成本的详细信息,请参见附录 D.5)。 每个模型的详细结果在附录的表 6 中提供。 可以观察到一些模式。 首先,vision transformer在性能/计算权衡方面主导了 ResNet。 ViT 使用大约 少了2 – 4 倍的计算来获得相同的性能(5 个数据集的平均值)。 其次,混合模型在较小的计算预算下略胜于 ViT,但对于较大的模型,这种差异消失了。 这个结果有些出人意料,因为人们可能期望卷积局部特征处理能够在任何规模下辅助 ViT。 第三,Vision Transformers 似乎不会在尝试的范围内饱和,从而推动未来的扩展工作。
其次,我们在9M、30M和90M的随机子集以及完整的JFT-300M数据集上训练我们的模型。我们不对较小的子集执行额外的正则化,而是对所有设置使用相同的超参数。这样,我们就可以评估模型的内在性质,而不是正则化的影响。然而,我们确实使用了early stoping,并报告了在训练期间获得的最佳验证准确性。为了节省计算量,我们报告了Few-shot的线性精度,而不是全微调精度。图4包含了这些结果。在较小的数据集上,Vision Transformer比ResNets过拟合更多。例如,ViT-B/32比ResNet50略快;它在9M子集上表现得更差,但在90M+子集上表现得更好。ResNet152x2和ViT-L/16也是如此。这一结果强化了一种直觉,即卷积归纳偏差对于较小的数据集是有用的,但对于较大的数据集,直接从数据中学习相关模式就足够了,甚至是有益的。
总的来说,ImageNet上的Few-shot结果(图4),以及VTAB上的低数据结果(表2)似乎很适合非常低的数据传输。进一步分析ViT的Few-shot特性是未来工作的一个令人兴奋的方向。
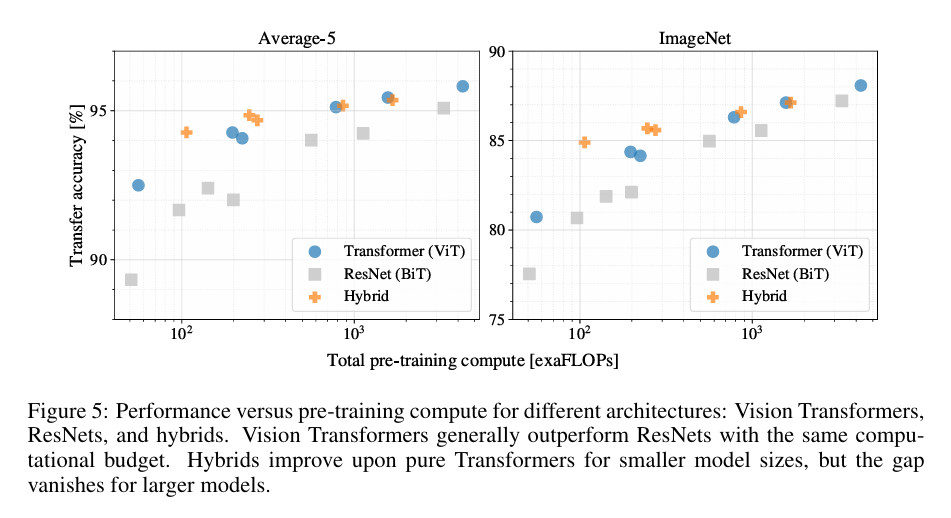
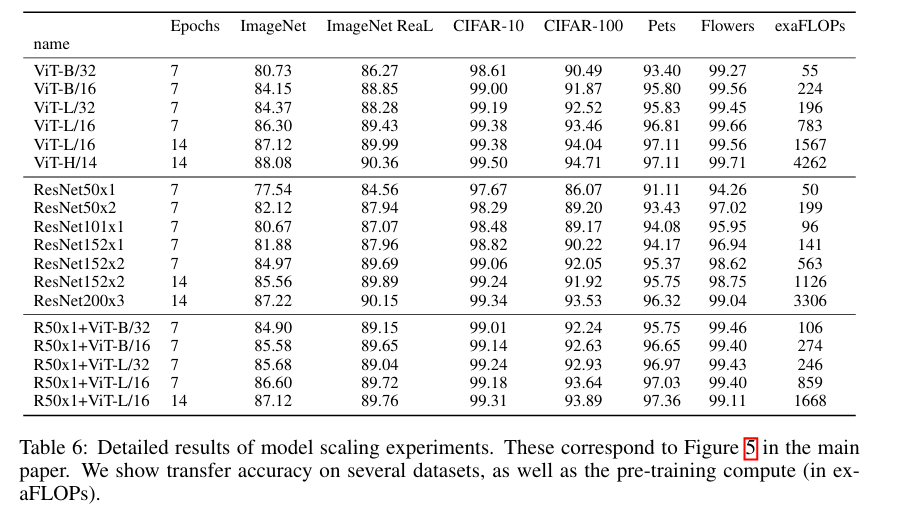
图5展示了模型在不同预训练计算成本情况下的迁移性能
表6展示了模型缩放实验的详细结果;
结论:ViT在性能 / 算力权衡中显著优于 ResNet。
缩放实验
理解模型在不同规模下的行为和性能变化,从而指导模型设计和选择合适的模型配置、寻找模型性能、计算成本和数据需求之间的最佳平衡点,以提高模型的效率和泛化能力;
4.5 Vision Transformer 内部机制分析
翻译
为了开始理解视觉转换器如何处理图像数据,我们分析了它的内部表示。Vision Transformer的第一层线性地投射了扁平的patch到一个低维空间(Eq. 1).图7(左)显示了学习到的embeding过滤器的顶部主成分。这些组件类似于每个patch内精细结构的低维表示的可信基函数。
投影结束后,将学习到的位置embeding添加到patch表示中。从图7(中)可以看出,模型通过位置embeding的相似性来学习对图像内的距离进行编码,即越近的斑块往往具有更多相似的位置embeding。此外,还会出现行-列结构;同一行/列中的patch具有类似的embeding。最后,对于较大的网格,正弦结构有时是明显的(附录D)。位置embeding学习了表示二维图像拓扑,这解释了为什么手工制作的二维感知嵌入变体没有产生改进(附录D.4)。
自我注意允许ViT整合整个图像的信息,即使是在最低的层。我们将研究该网络在多大程度上利用了这种能力。具体来说,我们根据注意力权重计算信息在被整合过的图像空间中的平均距离(图7,右)。这种“注意距离”类似于cnn中的接受野大小。我们发现,一些头部关注了已经在最低层的大部分图像,这表明模型确实使用了全局集成信息的能力。其他的注意力头脑在低层的注意距离一直很小。这种高度局部化的注意在transformer之前应用ResNet的混合模型中不那么明显(图7,右),这表明它可能在cnn中具有与早期卷积层类似的功能。此外,注意距离随着网络深度的增加而增加。在全球范围内,我们发现该模型关注的是与分类有语义相关的图像区域(图6)。
图7:左:ViT-L/32 RGB 值的初始线性embedding滤波器。 中:ViT-L/32 的position embedding的相似性。 右:按heads和网络深度划分的参与区域大小。

图6:从输出token到输入空间的注意力的代表性示例

结论:
1、模型使用了全局集成信息的能力。其他注意力head在低层中始终具有较小的注意力距离;
2、该模型关注与分类语义相关的图像区域。
4.6 自监督学习
翻译
transformer在NLP任务上的表现出了令人印象深刻的表现。然而,他们的成功不仅来自于他们优秀的可伸缩性,而且还来自于大规模的自我监督的预训练.我们还模拟了BERT中使用的掩码语言建模任务,对自我监督的掩码patch预测进行了初步的探索。通过自我监督预训练,我们较小的ViT-B/16模型在ImageNet上达到了79.9%的准确率,比从头开始训练显著提高了2%,但仍比监督预训练低4%。附录B.1.2包含了更多的细节。我们将对比预训练的探索(Chen等人,2020b;他等人,2020年;Bachman等人,2019年;H‘enaff等人,2020年)留给未来的工作。
作者模仿了 BERT 中使用的masked语言建模任务,比从头训练精确度高,但效果还不如监督训练,这就留给未来的探索了。
5 结论
翻译
我们探索了transformer在图像识别中的直接应用。与之前在计算机视觉中使用自注意的工作不同,除了最初的patch提取步骤外,我们没有在架构中引入特定于图像的归纳偏差。相反,我们将图像解释为一系列patch,并使用NLP中使用的标准变压器编码器对其进行处理。这种简单但可扩展的策略在结合大型数据集上的预训练时,工作得惊人地好。因此,Vision Transformer在许多图像分类数据集上匹配或超过了最先进的状态,而是相对便宜的预训练。
虽然这些初步结果令人鼓舞,但仍存在许多挑战。一是将ViT应用于其他计算机视觉任务,如检测和分割。我们的研究结果,加上Carion等人(2020年)的研究结果,表明了这种方法的前景。另一个挑战是继续探索自我监督的训练前方法。我们最初的实验表明,自我监督预训练有所改进,但自我监督预训练和大规模监督预训练之间仍存在很大的差距。最后,ViT的进一步扩展可能会导致性能的提高。
本文工作:
本文主要将图片处理成 patch 序列,然后使用 Transformer 去处理,取得了接近或超过卷积神经网络的结果,同时训练起来也更快。
未来展望:
1、将ViT应用于其他计算机视觉任务,如检测和分割。
2、继续探索自我监督的预训练方法。
3、可以进一步扩大ViT的规模,随着模型尺寸的增加,性能似乎还没有饱和。