MetaSegNet:用于遥感图像语义分割的元数据协同视觉-语言表征学习
期刊 IEEE Transactions on Geoscience and Remote Sensing (IEEE TGRS)
24年十月份出版
Dr. Libo Wang (王立波) – Homepage 作者GitHub主页 但并未提到代码开源的字样
简介
本论文区别于纯视觉模型,引入视觉-语言架构,实现对文本特征与视觉特征的跨模态融合
其中生成文本的依赖因素元数据的获取方式:
专业遥感与GIS软件
- NVI:加载影像后,通过
File > File Information或右键图层选择View Metadata,可查看波段、坐标系、获取时间等元数据。 - ERDAS IMAGINE:使用
Metadata工具直接查看影像的投影、传感器参数等信息。 - ArcGIS/ArcGIS Pro:在 ArcCatalog 中右键影像文件,选择
Item Description > Metadata;或在 ArcMap 中右键图层,通过Properties > Metadata查看。 - QGIS:加载影像后,右键图层选择
Properties > Information查看核心元数据(如坐标系、分辨率),或通过Metadata选项卡查看完整 XML 格式元数据。
命令行与编程库
GDAL(跨平台工具):
- 命令行:使用
gdalinfo your_image.tif,可输出影像的坐标系、波段数、分辨率等详细元数据,支持 JSON 格式输出(gdalinfo --json your_image.tif)。 - Python 编程:通过 GDAL 绑定读取元数据
- Rasterio(Python 库)
- ExifTool:命令行输入
exiftool your_image.tif,可读取遥感影像(如 GeoTIFF)的私有标签和元数据。
在线平台与数据源
- Landsat 数据:通过 USGS EarthExplorer 平台下载影像时,可直接查看元数据(如成像时间、云量、轨道号)。
- Sentinel 数据:在 Copernicus Open Access Hub 搜索影像,点击名称即可查看基础元数据;下载后解压包中的
manifest.xml文件包含完整技术参数。
文件直接查看
- 部分遥感影像(如 Landsat 的 MTL 文件、Sentinel 的 XML 文件)会附带独立的元数据文件,可直接用文本编辑器(如记事本)打开查看,例如 Landsat 的 MTL 文件会详细记录成像时间、传感器类型、坐标范围等信息。
0 摘要
摘要
遥感图像语义分割在土地利用 / 土地覆盖(LULC)制图、环境监测和可持续发展等一系列地球观测应用中发挥着至关重要的作用。在人工智能快速发展的推动下,深度学习(DL)已成为语义分割的主流技术,并在遥感领域取得了多项突破性进展。然而,大多数基于深度学习的方法仅关注单模态视觉数据,却忽略了现实世界中丰富的多模态信息。文本等非视觉数据能够从现实世界中获取额外知识,进而增强视觉模型的可解释性、可靠性和泛化能力。受此启发,本文提出了一种新颖的元数据协同分割网络(MetaSegNet),该网络将视觉 – 语言表征学习应用于遥感图像语义分割任务。与仅使用单模态视觉数据的常规模型结构不同,本文从可免费获取的遥感图像元数据中提取关键特征(如气候带),并借助通用的 ChatGPT 将其转换为地理文本提示。随后,构建图像编码器、文本编码器以及跨模态注意力融合子网络,分别用于提取图像和文本特征,并实现图文交互。得益于这种设计,所提出的 MetaSegNet 不仅在零样本测试中展现出卓越的泛化能力,而且在大规模 OpenEarthMap 数据集(平均交并比(mIoU)为 70.4%)、波茨坦(Potsdam)数据集(平均 F1 分数为 93.3%)以及 LoveDA 数据集(mIoU 为 52.0%)上,均取得了与当前最先进语义分割方法相当的精度。
1、(动机)大多数基于深度学习的方法仅关注单模态视觉数据,却忽略了现实世界中丰富的多模态信息。
(ps:单模态信息为如纯图像纯文本等这种形式单一、专注于某一种感官或数据类型的传递,而多模态信息为结合多种模态(两种及以上信息类型共同表达),多形式协同,不同模态信息可互补或强化,降低理解门槛)
2、文本等非视觉数据能够从现实世界中获取额外知识,进而增强视觉模型的可解释性、可靠性和泛化能力
3、本文提出一种新颖的元数据协同分割网络MetaSegNet,该网络将视觉-语言表征学习应用于遥感图像语义分割任务,就此具体而言,本模型可从免费获取的遥感图像元数据中提取关键特征,例如图像拍摄所在的气候带等,并借助通用的ChatGPT将其转换为地理文本提示。
(ps:元数据是描述主数据的信息,在此主数据可理解为遥感图像中类别的特征文字描述,相当于给这些数据加标签或说明书,帮助模型快速学习、理解、查找主数据)
4、构建图像编码器、语言解码器以及跨模态注意力融合子网络,分别用于提取图像和文本特征,并实现图文交互。(ps:跨模态即图像与文字间的交互)
5、本文使用数据集OpenEarthMap、LoveDA、Potsdam,在该三个数据集上分别展开实验,MIoU平均交互比分别为70.4%、93.3%、52.0%,取得与当前最先进语义分割方法相当的精度。
1 引言
翻译
随着传感器技术的不断进步,全球范围内捕获的遥感数据种类日益丰富、数量持续增长。海量遥感大数据的涌现,不仅极大地推动了地球观测领域的发展,也给数据解译方法带来了巨大挑战 [1]。作为最有效的解译方法之一,语义分割旨在实现像素级分类,其支撑着众多地球观测应用 [2],包括土地利用 / 土地覆盖(LULC)制图 [3]、云检测 [4,5]、森林与湿地调查 [6-8]、农田监测 [9]、建筑物提取 [10] 以及城市可持续发展 [11] 等。
过去十年见证了深度学习(DL)[12] 在语义分割领域的成功应用。自从全卷积网络(FCN)[13] 问世以来,具备自动特征提取和强大表征能力的卷积神经网络(CNNs)逐渐取代了传统的机器学习方法,成为语义分割的主流技术。多年来,众多研究者致力于开发基于卷积神经网络的遥感图像语义分割方法,极大地推动了该领域的发展 [14]。Maggiori 等人 [15] 设计了一种端到端的卷积神经网络用于大规模遥感图像分割,并在土地利用 / 土地覆盖制图中展现出优异性能。Diakogiannis 等人 [16] 结合编码器 – 解码器结构和残差连接的优势进行网络设计,在语义分割任务中取得了出色成果。然而,卷积操作的局部感受野特性使其无法捕捉长距离依赖关系,这在细粒度语义分割任务中存在局限性 [17]。为解决这一问题,部分研究者开始将空间注意力、自注意力等多种注意力机制融入网络,开发出注意力融合卷积神经网络 [18,19]。与此同时,另有研究者将 Transformer [20] 应用于视觉特征的长距离依赖建模 [21]。
上述基于卷积神经网络和 Transformer 的方法极大地改进了遥感图像语义分割中的视觉特征学习。但由于依赖单模态推理模式,这些方法在保证分类结果可靠性方面存在局限。为此,研究者们尝试引入多模态数据作为辅助信息,以提升模型的可靠性 [22]。常见的方案包括:1)将数字表面模型(DSM)与光学遥感图像相结合,弥补二维图像中地物的高度信息 [23];2)融合合成孔径雷达(SAR)数据与光学数据,以减轻云层的影响 [24];3)将三维点云与 RGB 图像融合,补充颜色和纹理信息 [25]。
综上所述,遥感语义分割网络的主要架构可分为三类:1)标准编码器 – 解码器架构,能够输出细粒度的分割结果,如图 1(a)所示;2)双路径架构,可同时捕捉全局上下文和空间细节信息,如图 1(b)所示;3)多模态架构,通过引入多模态信息实现互补,如图 1(c)所示。此外,得益于大型语言模型(LLMs)的显著成果,视觉 – 语言表征学习或视觉语言模型(VLM)已成为计算机视觉和遥感领域的研究热点 [26-32]。特别是,一种新颖的视觉 – 语言架构已被应用于语义分割任务 [33,34],如图 1(d)所示。该架构通常包含文本编码器、图像编码器以及用于图文特征融合的解码器。由于文本能够从现实世界中获取额外信息或知识 [35],因此视觉 – 语言架构比纯视觉模型具有更高的可靠性 [36]。对于遥感图像而言,文本信息可以描述图像的元特征(如分辨率、获取时间、地形、气候带等)或引入地理知识,从而助力遥感图像的智能解译 [27]。
受此启发,本文旨在挖掘遥感图像的元数据,并引入基于知识的地理文本提示用于视觉 – 语言表征学习,进而实现更精准、可靠的分割结果。具体而言,本文提出了一种元数据协同分割网络,即 MetaSegNet。该网络采用多模态视觉 – 语言架构,由文本编码器、图像编码器以及专门设计的跨模态注意力融合解码器(CAFDecoder)构成。文本编码器采用通用语言 Transformer(BERT)[37] 对文本提示进行编码,提取文本特征。值得注意的是,本文利用 ChatGPT [38] 生成基于知识的地理文本提示。图像编码器则采用通用的 Swin Transformer [39] 提取图像特征。最后,CAFDecoder 整合文本和图像特征,并输出分割掩码。本文的主要贡献总结如下:
1)提出了一种基于多模态视觉 – 语言架构的新颖元数据协同推理框架。据我们所知,本文首次挖掘可免费获取的图像元数据,并将其转换为基于知识的地理文本提示,以提升遥感分割模型的可靠性。
2)设计了基于 ChatGPT 的处理流程,通过查询从图像元数据中提取的特定气候带下的地物特征,生成专业的地理文本提示。
3)设计了一种即插即用的 CAFDecoder,能够有效整合异质图文特征,增强模态内和模态间的依赖关系,从而丰富高层语义内容。
本文其余部分的结构安排如下:第二部分将详细介绍所提出的 MetaSegNet 的结构、推理过程以及所设计的 CAFDecoder;第三部分通过消融实验验证 CAFDecoder 的有效性、文本提示的影响以及视觉 – 语言架构的零样本泛化能力,并在三个公开数据集上与一系列先进的分割模型进行对比;第四部分进行全面讨论;第五部分对全文进行总结与展望。
1、多数依赖单模态推理模型的基于卷积神经网络在保证分类结果可靠性方面存在局限。
2、研究者尝试引入多模态数据作为辅助信息,常见方案:1)将数字表面模型(DSM)与光学遥感图像相结合,弥补二维图像中地物的高度信息 [23];2)融合合成孔径雷达(SAR)数据与光学数据,以减轻云层的影响 [24];3)将三维点云与 RGB 图像融合,补充颜色和纹理信息 [25]。
3、遥感语义分割网络的主要架构可分为三类:1)标准编码器 – 解码器架构,能够输出细粒度的分割结果,如图 1(a)所示;2)双路径架构,可同时捕捉全局上下文和空间细节信息,如图 1(b)所示;3)多模态架构,通过引入多模态信息实现互补,如图 1(c)所示。此外,得益于大型语言模型(LLMs)的显著成果,视觉 – 语言表征学习或视觉语言模型(VLM)已成为计算机视觉和遥感领域的研究热点 [26-32]。特别是,一种新颖的视觉 – 语言架构已被应用于语义分割任务 [33,34],如图 1(d)所示。该架构通常包含文本编码器、图像编码器以及用于图文特征融合的解码器。
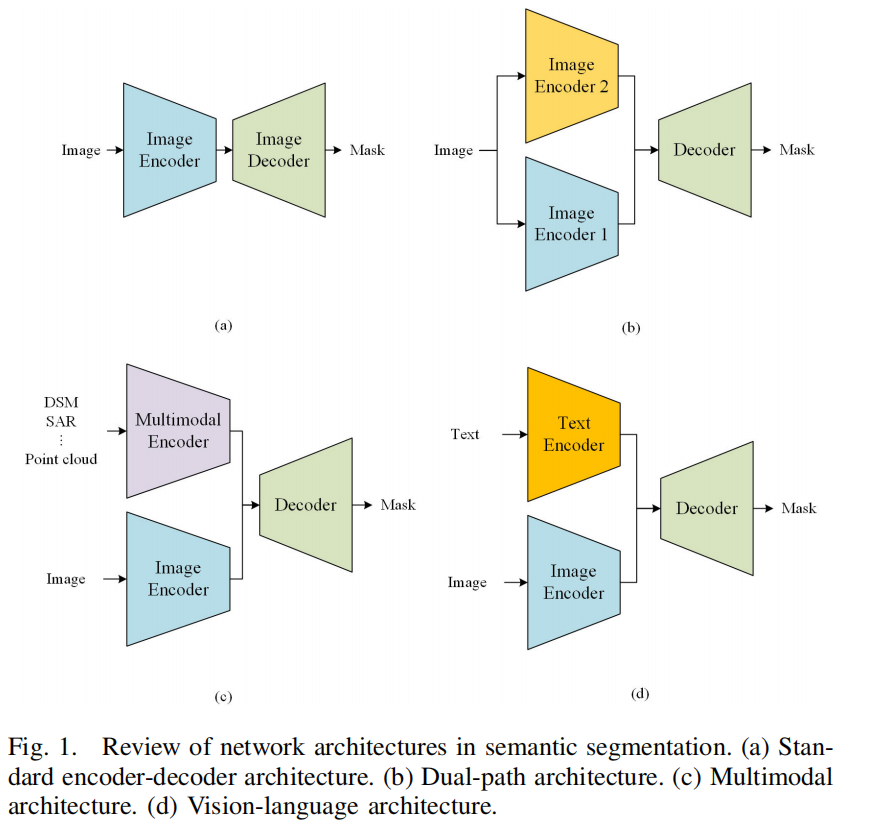
图1. 语义分割中的网络架构综述 (a)标准编码器 – 解码器架构(b)双路径架构(c)多模态架构(d)视觉 – 语言架构
文本能够从现实世界中获取额外信息或知识,因此视觉-语言架构比纯视觉模型具有更高的可靠性。
遥感图像中的文本信息可以描述图像的元特征(如分辨率、获取时间、地形、气候带等)或引入地理知识,从而助力遥感图像的只能解译。
4、本文旨在挖掘遥感图像的元数据,引入基于知识的地理文本提示用于视觉-语言表征学习。本文成果:提出一种元数据协同分割网络MetaSegNet用于多模态视觉-语言架构,由文本编码器、图像编码器及其专门设计跨模态注意力融合解码器CAFDecoder构成。具体而言:
基于多模态视觉-语言架构的新颖元数据协同推理框架本文首次挖掘可免费获取的图像元数据并将其转换为基于知识的地理文本提示,以提升遥感分割模型的可靠性。
基于ChatGPT的处理流程通过查询从图像元数据中提取的特定气候带下的地物特征,生成专业的地理文本提示。
跨模态注意力融合解码器CAFDecoder能够有效整合异质图文特征,增强模态内和模态间的依赖关系,从而丰富高层语义内容。
2 方法原理
2.1 整体架构
翻译
如图 2 所示,所提出的 MetaSegNet 由图像编码器、文本编码器和 CAFDecoder 构成。此外,用于将图像元数据转换为文本提示的 ChatGPT 处理流程也是该网络的重要组成部分。本文选择 Swin Transformer 的基础版本作为图像编码器,因其支持大尺寸输入且对 GPU 内存需求较低。同时,选用通用语言 Transformer(BERT)作为文本编码器。最后,通过 CAFDecoder 整合提取到的图像和文本特征,生成分割掩码。各组件的详细说明将在后续章节展开。
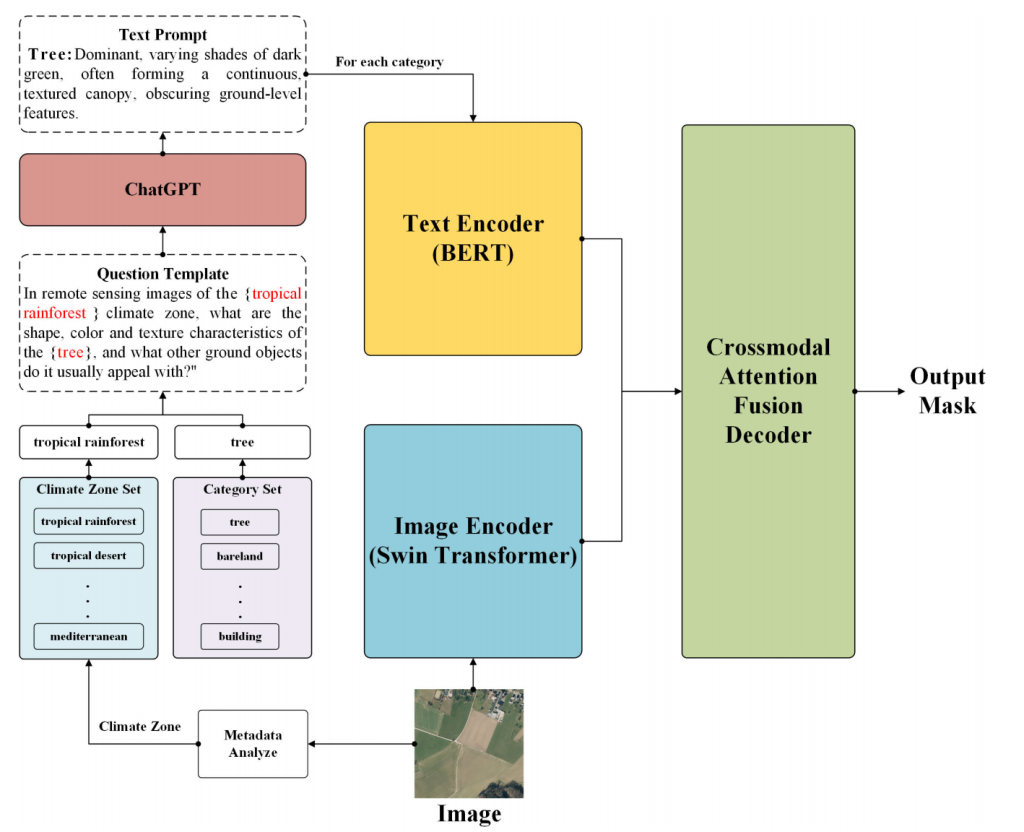
图1.MetaSegNet网络概述
整体架构可分为如下三部分:
元数据分析与文本提示生成
- 元数据分析(Metadata Analyze):首先对输入的遥感图像进行元数据分析,提取其所属的气候带(Climate Zone)(如热带雨林、热带沙漠、地中海气候等)。
- 文本提示生成(Text Prompt Generation)结合图像的气候带和地物类别(Category Set,如树木、裸地、建筑物等),使用问题模板(Question Template)生成针对每个类别的查询问题,例如“在热带雨林气候带的遥感图像中,树木的形状、颜色、纹理特征是什么,通常与哪些其他地物共存?”,然后将这些问题输入到ChatGPT,生成描述性的文本提示(Text Prompt),例如对图中树木的描述:“主要为深绿色的不同色调,常形成连续的纹理树冠,遮挡地面特征。”
多模态特征提取
- 文本编码(Text Encoder(BERT))使用BERT(通用语言Transformer)对生成的文本提示进行编码,提取文本特征
- 图像编码(Image Encoder(Swin Transformer))使用Swin Transformer对输入的遥感图像进行编码,提取图像特征
跨模态特征融合与分割输出
- 跨模态注意力融合解码器(Crossmodel Attention Fusion Decoder)整合文本特征和图像特征,通过跨模态注意力机制实现图文信息的交互融合,最终输出分割掩码(output mask),完成遥感图像的语义分割任务。
2.2 基于ChatGPT的文本提示生成
翻译
大型语言模型(LLMs)在问答、文本生成等众多实际应用中同时展现出有效性和泛化能力。顺应这一趋势,本文采用知名的 ChatGPT,从图像元数据中生成地理文本提示。如图 1 所示,文本提示生成的主要步骤如下:1)从图像元数据中提取关键属性(如地理坐标或区域);2)通过查询柯本 – 盖格(Köppen-Geiger)气候带世界地图 [40],确定该遥感图像所属的气候带;3)针对每个类别,利用设计好的问题模板生成问题,并向 ChatGPT 提问以获取文本提示;4)最后,将各个文本提示合并,生成完整的文本提示,并输入至文本编码器。借助这种基于 ChatGPT 的文本提示生成方法,每幅遥感图像都附带了对每个类别的形状、颜色、纹理特征以及潜在周边地物的详细描述。
1、采用知名的ChatGPT,从图像元数据中生成地理文本提示
2、文本提示的主要步骤:①从图像元数据提取关键属性(例如地理坐标或区域)、②通过查询柯本-盖格生成气候带世界地图确定该遥感图像所属的气候带、③针对每个类别利用设计好的问题模板生成对应问题并向ChatGPT提问以获取文本提示、④将各个文本提示合并,生成完整的文本提示并输入到文本编码器中。
2.3 跨模态注意力融合解码器(CAFDecoder)
翻译
人类大脑中视觉与语言的交互频繁发生,这有助于我们理解这个多模态世界。随着大规模多模态预训练的成功,视觉 – 语言模型已成为现代人工智能研究中日益核心的解决方案 [41]。由于图像和文本数据之间存在显著差异,跨模态图文特征对齐与融合是视觉 – 语言表征学习的关键因素 [42]。为解决这一问题,本文设计了 CAFDecoder,该解码器主要由图文匹配损失模块、图文对齐模块和图文融合模块三部分组成,如图 3 所示。
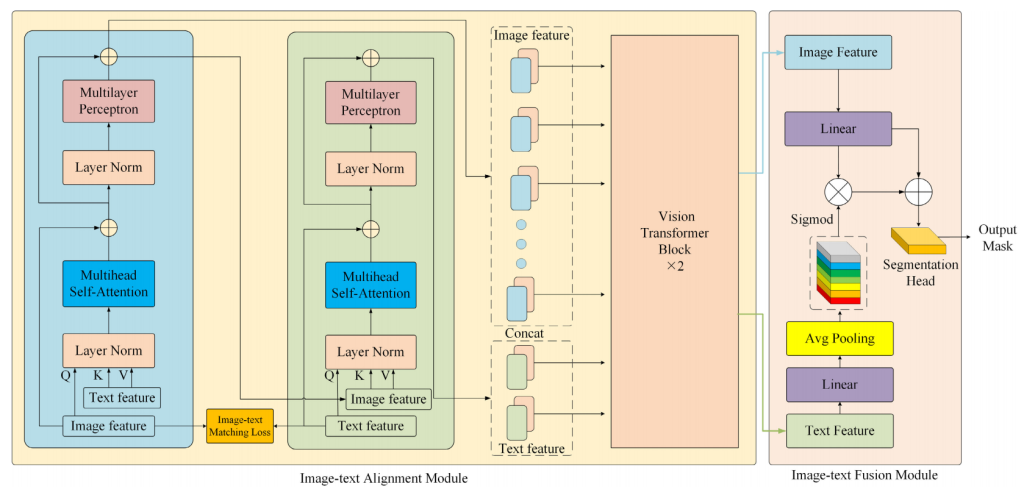
图2.CAFDecoder的架构
跨模态注意力融合解码器CAFDecoder,分为两个部分,图文对齐模式、图文融合模式
图文对齐模式该模块的目标是缩小图像特征与文本特征之间的模态差异,建立初始关联。
- 多模态自注意力交互左侧分支:以图像特征作为查询Q,文字特征作为键K和值V,通过多头自注意力实现“图像引导的文字特征关注”,随后经过层归一化和多层感知机完成特征变换,保证特征一致性,最终输出融合文本特征的图像特征,并将该图像特征通过跳跃连接作为右侧分支中的图像特征;右侧分支:以文本特征作为查询Q,图像特征作为键K和V,通过多头注意力机制实现“文本引导的图像特征关注”,同样经层归一化和多层感知机变换,输出融合图像特征的文本特征。
- 图文匹配损失(Image-text Matching Loss)计算图像与文本特征的匹配损失,强制两者在语义空间中对齐,进一步缩小模态间的差异。
- 视觉Transformer块(Vision Transformer Block×2)将上述交互后的图像特征和文本特征分别输入到两个两个Transformer块,增强模态内的长距离依赖关系;最后对文本特征执行拼接(concat)操作,为后续融合做准备
图文融合模块整合对齐后的图文特征,输出分割掩码
- 特征预处理首先图像特征:经线性变换,调整维度后经过sigmod激活函数生成注意力权重,其次文本特征:经过线性变换与全局池化操作提取全局文本知识,后与通过图像特征生成的注意力权重进行相乘
- 跨模态特征融合将上述分别处理之后的图像特征与文本特征进行残差连接整和原始图像特征,实现“文本知识对图像特征的增强”。
- 分割头输出(Segmentation Head)融合后的特征输入到分割头中,最终生成分割掩码(Output Mask),完成遥感图像的语义分割。
2.3.1 图文对齐模式

翻译
本文采用 “先对齐后融合” 的策略处理异质图文特征。首先,引入图文匹配损失以缩小图像特征与文本特征之间的模态差异。这一操作能够在两种特征之间建立初始关联,为后续处理中的图文特征融合奠定基础。图文匹配损失的详细计算过程如下:
最终,训练过程中使用的总损失L由图文匹配损失\(L_{itm}\)、骰子损失(Dice Loss)\(L_{dice}\)和交叉熵损失\(L_{ce}\)三部分组成,其计算公式如下:
\(\mathcal{L}_{dice}=1-\frac{2}{N}\sum_{n = 1}^{N}\sum_{k = 1}^{K}\frac{\hat{y}_{k}^{(n)}y_{k}^{(n)}}{\hat{y}_{k}^{(n)}+y_{k}^{(n)}}\)
如图 3 所示,分别将图像特征和文本特征作为查询向量,执行两次连续的跨模态注意力融合操作。通过这一操作,能够增强图像特征与文本特征之间的模态间关联。为进一步加强模态内交互,本文采用图文联合学习方案:首先将图像特征和文本特征组合成具有位置感知的一维序列,然后使用两个标准的视觉 Transformer 进行编码。两次连续跨模态注意力融合操作的计算公式如下:
其中,\(F_{img}\in\mathbb{R}^{B\times L_{1}\times C}\)和\(F_{text}\in\mathbb{R}^{B\times L_{2}\times C}\)分别表示图像特征和文本特征。B和C分别为批处理大小和通道数,\(L_{1}\)和\(L_{2}\)分别表示图像特征和文本特征的序列长度。在公式(1)和(2)中,N和K分别代表样本数量和类别数量。\(y^{(n)}\)和\(\hat{y}^{(n)}\)分别表示真实标签的独热向量及其对应的 softmax 输出,\(n\in[1,\cdots,N]\)。\(\hat{y}_{k}^{(n)}\)表示第n个样本属于第k类别的置信度。
2.3.2 图文融合模块
翻译
包含气候信息和地物特征的文本特征可作为跨模态特征融合的全局先验知识。因此,如图 3 所示,本文首先通过线性投影和平均池化操作,将文本特征转换为通道维度的全局先验信息。随后,对处理后的文本特征与图像特征执行乘法运算,并引入残差连接,从而完成图文融合。最后,将融合后的特征输入至分割头,输出分割掩码。
3 实验设置与数据集
3.1 数据集
1、本文实验在OpenEarthMap、LoveDA、Potsdam三个遥感图像数据集上进行展开。
3.1.1 OpenEarthMap数据集
翻译
OpenEarthMap 数据集是一个大规模高分辨率土地覆盖制图数据集 [43],包含 5000 幅图像,涵盖 8 种土地覆盖类别(裸地、牧场、已开发区域、道路、树木、水体、农田和建筑物),空间分辨率为 0.25-0.5 米,覆盖六大洲 44 个国家的 97 个区域。由于该数据集区域差异大、类别界限模糊且场景普遍复杂,其语义分割任务具有较大挑战性。在 OpenEarthMap 基准数据集中,每个区域的 RGB 图像被随机划分为训练集、验证集和测试集,分别包含 3000 幅、500 幅和 1500 幅图像。需要注意的是,测试集标签尚未公开,因此本文使用验证集来验证模型性能。在实验中,将输入图像统一调整为 1024×1024 像素大小的 patches,并且在训练和测试阶段采用水平翻转、垂直翻转等常见的数据增强策略。
3.1.2 LoveDA数据集
翻译
LoveDA 数据集 [44] 包含 5987 幅高分辨率光学遥感图像(地面采样距离(GSD)为 0.3 米),这些图像采集自中国的南京、常州和武汉三座城市。图像尺寸为 1024×1024 像素,土地覆盖类别包括建筑物、道路、水体、荒地、森林、农田和背景。具体而言,训练集使用 2522 幅图像,验证集使用 1669 幅图像,测试集使用官方提供的 1796 幅图像。该数据集涵盖城市和农村两种场景,因此具有相当大的挑战性。同样,根据亚热带季风气候带对文本提示进行调整。
3.1.3 Potsdam数据集
翻译
Potsdam 数据集包含 38 幅超高分辨率航空图像(地面采样距离为 5 厘米),图像尺寸为 6000×6000 像素,涉及 6 类地物(不透水面、低矮植被、树木、车辆、建筑物和杂波),包含 4 个多光谱波段(红、绿、蓝和近红外)以及数字表面模型(DSM)和归一化数字表面模型(NDSM)。在实验中,本文遵循官方的训练集、验证集和测试集划分方式,选用红、绿、蓝三个波段进行训练和测试。将原始图像切片裁剪为 1024×1024 像素大小的 patches 作为输入,并采用随机翻转的数据增强方法扩充训练样本。此外,波茨坦地区属于温带大陆性气候,因此根据该气候带对文本提示进行调整。
3.2 评价指标
翻译
本文采用总体准确率(OA)、平均交并比(mIoU)、F1 分数、精确率(Precision)和召回率(Recall)来评估模型性能,其定义如下:其中,TPk、FPk、TNk和FNk分别表示第k类地物的真阳性、假阳性、真阴性和假阴性数量。总体准确率(OA)的计算涵盖所有类别,包括背景像素。
1、评价指标使用总体准确率OA、平均交互比MIoU、F1分数、准确率、召回率
3.3 实验设置
翻译
所有实验模型均在 PyTorch 2.0 框架下,基于单块 NVIDIA GTX 4090 GPU 实现。采用 AdamW 优化器训练所有模型,并使用早停(early stopping)策略防止过拟合。初始学习率设置为3e – 4,批处理大小设置为 2,权重衰减设置为2.5e – 4。最大训练轮次(epoch)为 45,并采用余弦策略调整学习率。特别地,在训练阶段冻结文本编码器 BERT 的参数。输入文本提示被填充至统一长度 250。此外,对于 1024×1024 像素大小的输入图像块,本文提出的 MetaSegNet 的帧率(FPS)达到 23.7,具有较强的竞争力。MetaSegNet 的总参数量为 39970 万,其中仅有四分之一为可训练参数。
1、实验框架使用PyTorch 2.0,算力资源单块NVIDIA GTX 4090 GPU,优化器AdamW,使用早停策略防止过拟合,批处理大小设置为 2,权重衰减设置为2.5e – 4。最大训练轮次45,输入文本提示被填充至统一长度250,输入图像块1024×1024像素
3.4 基准对比方法
翻译
基线模型(Baseline):该模型由 Swin Transformer(Swin – Base)[39] 和包含一系列上采样操作的分割头组成,是为与所提出的 MetaSegNet 进行消融实验而构建的纯视觉模型。
U – Net:U – Net [45] 是经典的全卷积神经网络,首次引入编码器 – 解码器结构用于语义分割任务。
DANet:DANet [46] 是一种基于注意力机制的卷积神经网络,融合了空间注意力和通道注意力,较早地探索了自注意力机制在语义分割中的应用潜力。
SegFormer:SegFormer [47] 是一种基于 Transformer 的全编码器 – 解码器网络,通过改进 Transformer 架构以实现密集预测。
CLIPSeg:CLIPSeg [33] 是一种遵循视觉 – 语言结构的多模态分割网络,通过引入文本或图像提示来增强语义分割性能。
先进语义分割方法:本文选取了一系列遥感图像和自然图像分割方法进行全面对比,包括 PSPNet [48]、DeeplabV3 + [49]、BoTNet [50]、Segmenter [51]、SwinUperNet [39]、V – FuseNet [23]、UFMG_4 [52]、ResUNet – a [16]、DDCM – Net [53]、LANet [54]、FarSeg [55]、FactSeg [56]、EaNet [57]、BANet [58]、ABCNet [59]、UNetFormer [17]、MANet [19]、DC – Swin [60]、SAPNet [61]、EMRT [62]、FTransUNet [63] 和 RS3Mamba [64]。
1、baseline:由Swin Transformer和包含一系列上采样操作的分割头组成。
2、对比模型:U-Net,DANet、SegFormer、CLIPSeg以及先进语义分割方法。
4 实验结果与分析
4.1 与当前最先进语义分割方法的定量对比
4.1.1 OpenEarthMap数据集
翻译
OpenEarthMap 是一个大规模土地覆盖制图数据集,其图像由高分辨率卫星或航空传感器捕获,覆盖全球不同城市。因此,在该数据集上实现高准确率具有很大挑战性。本文训练了多个先进的语义分割模型,并在 OpenEarthMap 验证集上进行了详细的对比实验。如表 1 所示,MetaSegNet 取得了最高的平均交并比(mIoU 为 70.4%),并且在大多数特定类别上均表现出优势。具体而言,本文提出的方法不仅比基于卷积神经网络的模型(如 U – Net、DANet 和 MANet)的 mIoU 至少高出 6.4%,比先进的基于 Transformer 的网络 UNetFormer 高出 2.4%,还比最新的基于 Mamba 的方法 RS³Mamba 高出 5.9%。此外,可视化结果(见图 4)也表明,与最新的卷积神经网络和视觉 Transformer 相比,本文提出的 MetaSegNet 具有明显优势。
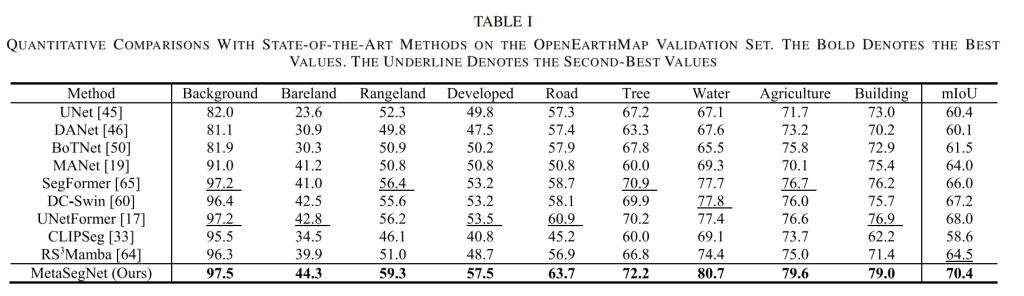
表1.在OpenEarthMap验证集上与最先进方法的定量比较。粗体表示最佳值,下划线表示次佳值
1、本文MetaSegNet模型在OpenEarthMap测试集上,每个指标均取得最佳值。
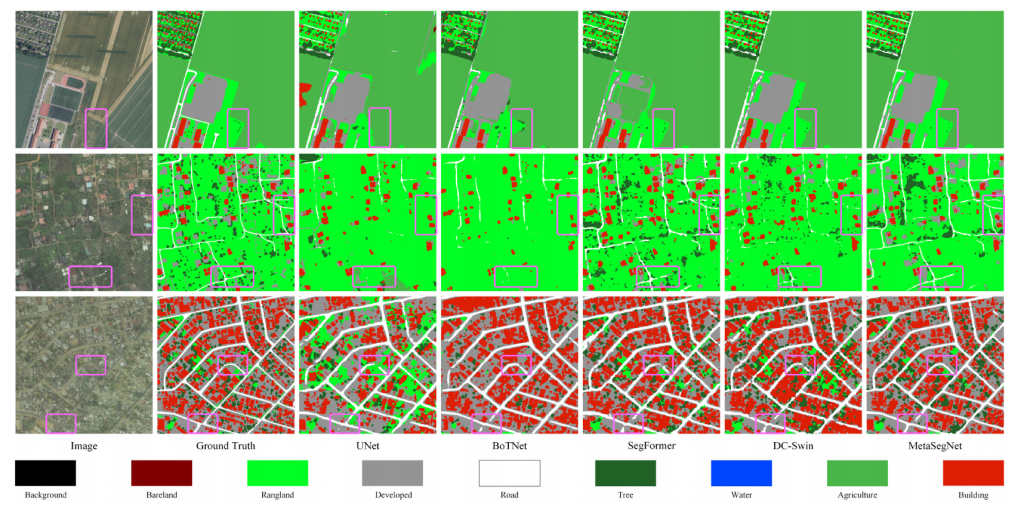
图4.在OpenEarthMap数据集上的可视化对比
4.1.2 Potsdam数据集
翻译
国际摄影测量与遥感学会(ISPRS)的 Potsdam 数据集是验证遥感图像分割方法性能的常用数据集。目前,许多专门设计的网络在该数据集上都取得了出色的性能。在本节中,本文将证明所提出的 MetaSegNet 与这些当前最先进的网络相比,能够取得具有竞争力的成绩。如表 2 所示,MetaSegNet 在 Potsdam 测试集上的平均 F1 分数为 93.3%,总体准确率(OA)为 92.0%,平均交并比(mIoU)为 87.6%。MetaSegNet 的结果不仅比基于卷积神经网络的分割模型 EaNet 的平均 F1 分数高出 2.6%,还比最新的基于 Transformer 的网络 FTransUNet 的 mIoU 高出 1.4%。本文还提供了与 UNetFormer 的可视化对比结果,如图 5 所示,MetaSegNet 的整体分割性能同样出色。
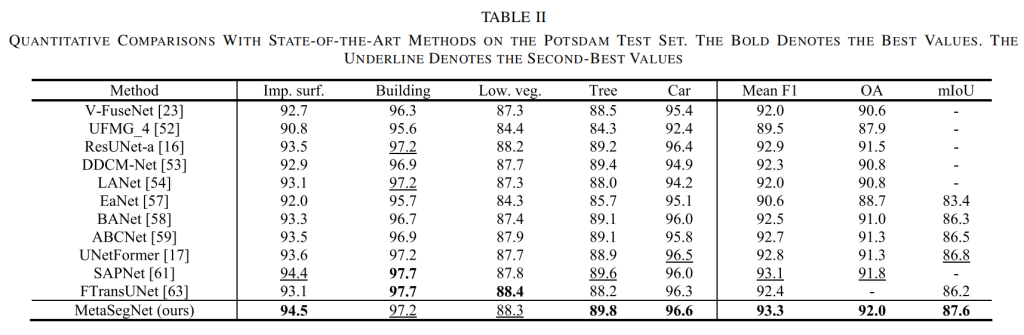
表2.在Potsdam验证集上与最先进方法的定量比较。粗体表示最佳值,下划线表示次佳值
1、MetaSegNet模型在Potsdam数据集上的分割性能同样出色
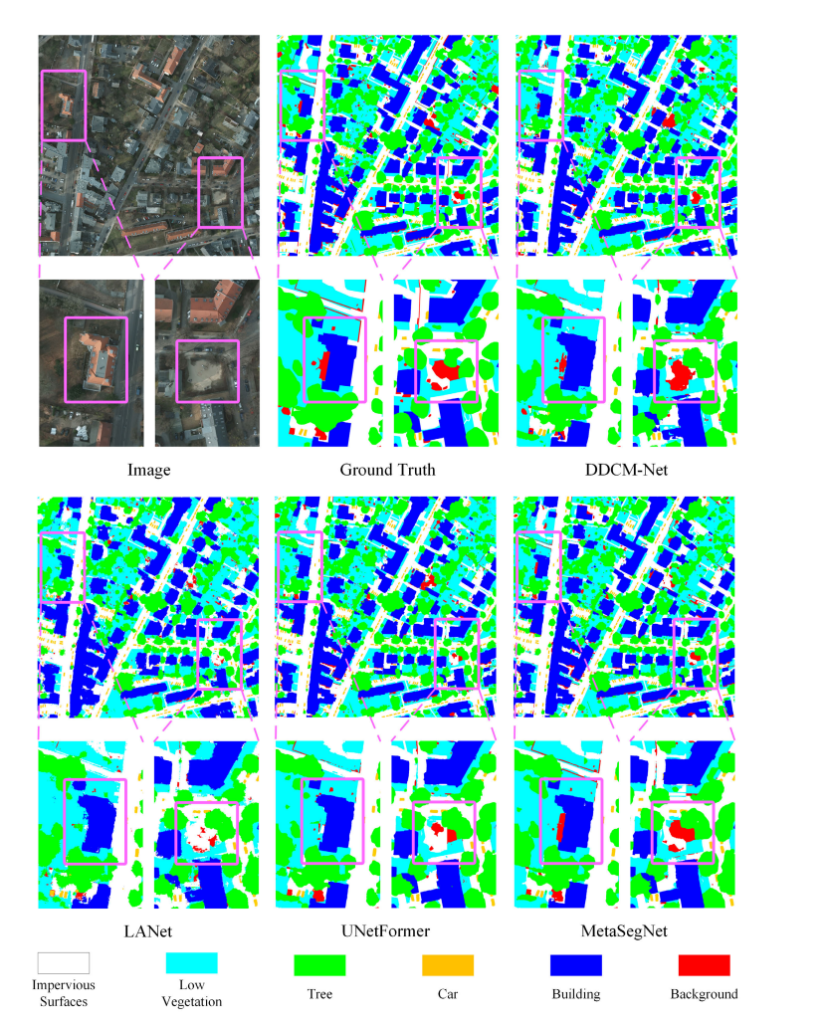
图5.在Potsdam数据集上的可视化对比
4.1.3 LoveDA数据集
翻译
为进一步测试所提出的 MetaSegNet,本文在 LoveDA 数据集上进行了实验。如表 3 所示,MetaSegNet 取得了最高的 mIoU(52.0%)。这些结果表明,与其他卷积神经网络和 Transformer 相比,视觉 – 语言结构和信息丰富的文本提示在处理复杂遥感场景时具有显著优势。此外,LoveDA 验证集上的可视化结果(见图 6)也表明,本文方法在特定类别(尤其是道路和建筑物)的分割上具有优势。
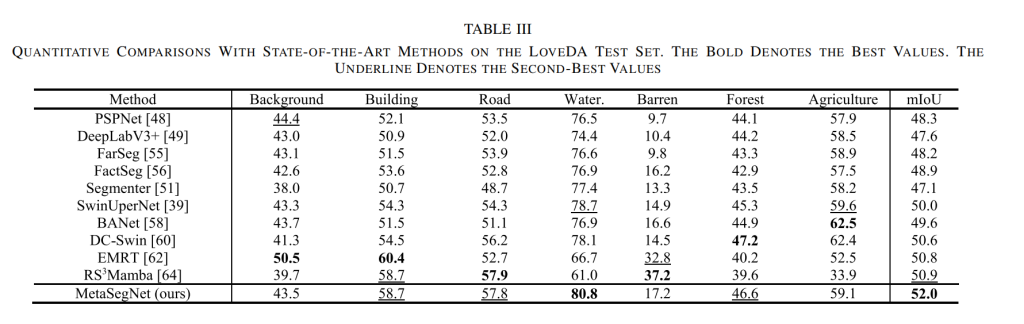
表3.在LoveDA验证集上与最先进方法的定量比较。粗体表示最佳值,下划线表示次佳值
1、MetaSegNet在LoveDA数据集上,取得最佳MIoU,其在特定类别例如道路与建筑物分割上具有优势
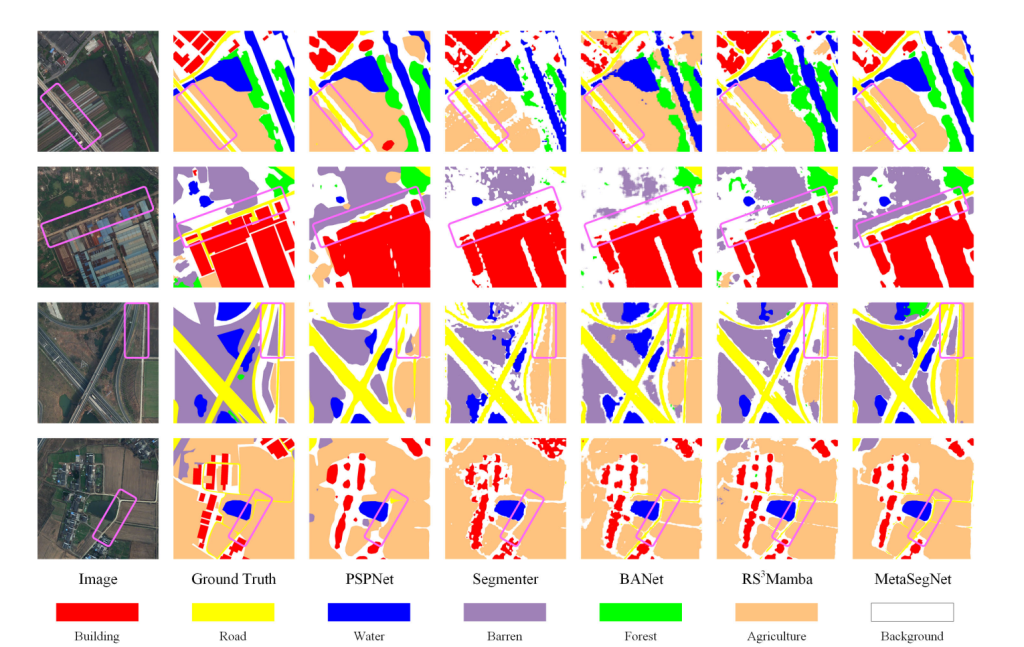
图6.在LoveDA数据集上的可视化对比
4.2 消融试验
4.2.1 MetaSegNet各组件的作用
翻译
为评估图文对齐模块(记为 Alignment)和图文融合模块(记为 Fusion)的性能,本文在 OpenEarthMap 数据集上进行了消融实验,结果如表 4 所示。引入图文对齐模块后,模型的 mIoU 提升了 2.5%,这表明该模块对于图文特征融合具有有效性和必要性。此外,加入图文融合模块后,mIoU 进一步提升了 0.8%,这体现出该模块在视觉 – 语言表征学习中的有效性。
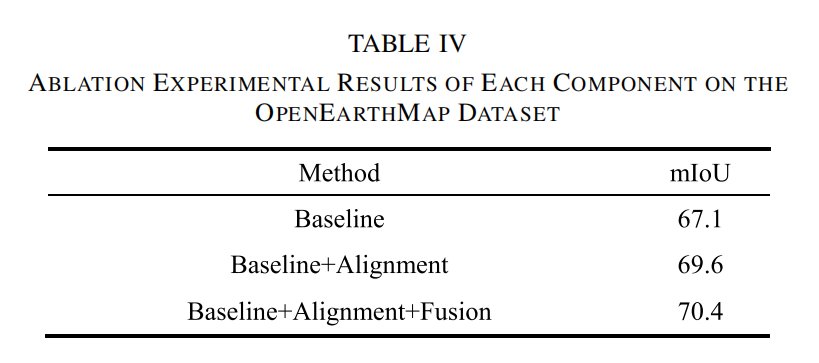
表4.各组件在OpenEarthMap数据集上的消融实验结果
1、在OpenEarthMap数据集上验证图文对齐模块(Alignment)与图文融合模块(Fusion)的性能,逐个向baseline上加入模块,MIoU随之增高
4.2.2 文本提示的影响
翻译
为验证文本提示的作用以及挖掘图像元数据的重要性,本文在消融实验中用简单文本提示替换了基于 ChatGPT 的文本提示。如表 5 所示,在 MetaSegNet 中使用简单文本提示会导致 mIoU 下降超过 0.5%,这表明专业且详细的文本提示具有重要意义。值得注意的是,不使用任何文本提示时,模型准确率会显著下降 3.3%,这一结果证明了视觉 – 语言模型相较于纯视觉模型的优势。此外,气候带对地物(尤其是植被)的影响通常大于对人工地物的影响。因此,本文选取树木、农田和建筑物这三类地物,进一步探究具有气候感知的文本提示的作用。结果显示,当使用非气候相关的文本提示时,建筑物类别的准确率下降幅度(0.3%)小于树木(0.6%)和农田(1.3%),这一现象不仅说明了基于知识的地理文本提示的重要性和优势,也间接证明了图文融合的有效性。

表5.文本提示词的影响
1、验证ChatGPT文本提示的作用以及挖掘图像元数据的重要性,分别在无文本提示、简单文本提示、ChatGPT文本提示条件进行实验,得到的数据说明了基于知识的地理文本提示的重要性和优势,也间接证明了图文融合的有效性。
4.2.3 零样本测试
翻译
为评估视觉 – 语言架构的泛化能力,本文选取 Potsdam 数据集,对比基线模型和 MetaSegNet 的零样本分割能力。首先在大规模 OpenEarthMap 数据集上对 MetaSegNet 和基线模型进行预训练,然后直接将其应用于 Potsdam 数据集。由于这两个数据集的类别不完全相同,因此仅计算重叠类别的交并比(IoU),即人工建筑物和自然树木。如表 6 所示,与基线模型相比,MetaSegNet 在建筑物类别 IoU(IoU – Building)上提升了 2.9%,在树木类别 IoU(IoU – Tree)上提升了 4.1%,这一结果表明视觉 – 语言模型比纯视觉模型具有更优异的泛化能力。

表6.在 Potsdam 数据集上的零样本测试
1、本文在Potsdam数据集上评估视觉 – 语言架构的泛化能力,对比基线模型与MetaSegNet的零样本分割能力:具体操作是首先在OpenEarthMap数据集上对MetaSegNet与基线模型进行预训练,然后直接将其应用于Potsdam数据集上。(ps:由于这两个数据集的类别不完全相同,因此仅计算重叠类别的交并比(IoU),即人工建筑物和自然树木。)
5 讨论
5.1 视觉-语言表征学习的优势
翻译
随着视觉 Transformer 和大型语言模型(LLMs)的发展,视觉 – 语言表征学习已成为一个极具前景的研究方向。受这一趋势启发,本文开发了具有视觉 – 语言结构的 MetaSegNet,旨在通过基于知识的地理文本提示提升遥感分割模型的可靠性。实验结果证实了这一设计思路的有效性。特别值得注意的是,本文发现与人工建筑物相比,与气候相关的文本提示能更显著地提高植被类别(如树木)的分类准确率。这种现象在零样本测试中更为明显,充分凸显了视觉 – 语言模型中图文关联的重要性。
5.2 大规模无监督预训练的潜力
翻译
值得一提的是,MetaSegNet 中使用的文本提示可完全从可免费获取的遥感图像元数据中提取。因此,如何利用这些免费元数据进行大规模无监督预训练,是一个极具研究价值的方向。未来,本文将深入探索这一领域,尤其关注其在大型遥感模型训练中的潜力,并进一步挖掘元数据的更多核心属性(如时间、空间分辨率等)及其对特定地物的影响。
5.3 基于知识的地理文本提示
翻译
文本是地理知识的良好载体。通过引入更多地理知识并进行文本提示微调,构建知识驱动的深度模型具有广阔前景。
6 结论
翻译
本文提出了一种新颖的视觉 – 语言网络(MetaSegNet),用于遥感图像语义分割。设计了基于 ChatGPT 的处理流程以生成基于知识的地理文本提示,并构建了跨模态注意力融合子网络,实现图文特征的交互与融合。消融实验表明,地理文本提示能够提升模型的可靠性,尤其对与文本相关的地物类别效果显著。此外,在 OpenEarthMap、Potsdam 和 LoveDA 三个数据集上的综合实验进一步证明了所提方法的优势以及视觉 – 语言表征学习的有效性。
1、成果:本文提出一种新颖的视觉-网络模型MetaSegNet用于遥感语义分割,设计了基于ChatGPT的处理流程以生成基于知识的地理文本提示,并构建了跨模态注意力融合子网络,实现图文特征的交互与融合。
2、通过实验表明:地理文本提示能够提升模型的可靠性,尤其对与文本相关的地物类别效果显著,进一步证明了所提方法的优势以及视觉 – 语言表征学习的有效性。