
[Submitted on 24 Jun 2024 (v1), last revised 11 Feb 2025 (this version, v3)]
简介(贡献)
1、本文设计了一种新颖的局部-全局类别感知策略,通过将局部类别中心作为中间感知单元,间接将像素与全局类别中心关联,有效缓解了遥感图像中的类内差异问题。
2、首次引入仿射变换块用于提取局部类别中心,以适应不同尺寸、形状和朝向的地理空间对象,从而很好地应对遥感图像的尺度与方向变化。
3、提出转为遥感图像特征设计的语义分割模型LOGCAN++。在三个遥感语义分割基准数据集上的大量实验结果表明,LOGCAN++优于其他最先进的方法,并且在精度与效率之间实现了更好的平衡。
0 摘要
翻译
遥感图像通常具有复杂背景、尺度和方向变化以及大的类内方差(intra-class variance)等特点。通用的语义分割方法通常未能充分研究上述问题,因此其在遥感图像分割上的性能受限。本文中,我们提出了 LOGCAN++,一个为遥感图像定制的语义分割模型,它由一个全局类别感知(Global Class Awareness, GCA)模块和若干个局部类别感知(Local Class Awareness, LCA)模块组成。GCA 模块捕获全局表示以进行类别级上下文建模,以减少背景噪声的干扰。LCA 模块生成局部类表示作为中间感知元素,以间接地将像素与全局类表示关联起来,旨在处理大的类内方差问题。特别地,我们在 LCA 模块中引入了仿射变换(affine transformations),用于自适应地提取局部类表示,以有效容忍遥感图像中的尺度和方向变化。在三个基准数据集上的大量实验表明,我们的 LOGCAN++ 优于当前主流的通用和遥感语义分割方法,并在速度和精度之间实现了更好的平衡。
关键词:类别感知;仿射变换;上下文建模;
(动机)1、提出遥感图像的三大典型特征:具有复杂背景、尺度和方向变化以及大的类内方差,指出通用语义分割方法在处理遥感图像的局限性。
(成果)2、提出一个:LOGCAN++的语义分割模型,该模型由一个全局类别感知模块(GCA模块,用来捕获全局表示以进行类别级上下文建模,以减少背景噪声的干扰)和若干个局部类别感知模块(LCA模块,生成局部类别表示作为中间感知元素以间接地将像素与全局类别表示关联起来,用于自适应地提取局部类别表示,以有效容忍遥感图像中的尺度和方向变化)组成。
3、通过三个基准数据集的大量实验表明,本文的LOGCAN++优于当前主流的通用和遥感语义分割方法,并在速度和精度之间实现了更好的平衡。
全局类别感知
GCA,帮助模型突破局部特征局限,捕捉类别级别的全局信息,从而减少背景干扰、统一类内特征差异、强化类别区分度,最终提升分类或分割任务的准确性与稳定性。
融合全局类别特征,从整幅数据中提取类别中心(某一类别的特征均值或核心表征,通过全图中某一类别的全部像素特征计算特征均值),让模型理解这一类事物整体“长什么样”,而非仅依赖单个像素或局部区域的碎片化特征。(这解决遥感图像中类内方差的问题)
抑制背景与噪声, 通过全局类别中心的“锚定”作用,引导模型忽略掉无关背景或干扰因素(如光影变化等),让目标像素的特征更贴近其所属的类别的全局中心,减少误分类。(这减少了遥感图像中复杂背景的问题)
统一类内方差,同一类别在数据中可能存在形态、尺寸、方向等差异(如不同季节、不同拍摄角度等的影响),GCA通过全局信息约束,缩小这类的“类内差异”,让模型对同一目标的判断更一致。(这减少遥感图像中同一类别尺寸、方向等差异对分类的影响)
全局类别感知主要就是根据某一类别的特征均值或核心表征,即类别中心,来减少遥感图像三大典型特征的消极影响,进而提升语义分割任务对像素类别分类的准确性。
局部类别感知
局部类别感知可以看作是对“全局类别感知”的补充与聚焦,它不依赖全图的类别中心,而是以局部区域的特征共性为判断基准,即单看整幅图的单个局部patch,以此解决遥感图像中“全局信息无法覆盖局部信息细节”的问题,即用全图层面的共性特征,会“平均掉”或“忽略掉”局部小区域的独特特征,例如:当一块区域中农田的像素占90%,水渠的像素占10%,当计算农田的全局类别中心时,特征会偏向农田的特征,而水渠的全局中心因样本少,特征会被农田的“特征均值”稀释。
不看全图中心,只看局部共性
局部类别感知不会计算全图某一类别的特征均值,而是将遥感图像划分为多个小的局部区域(比如每个像素为中心的3×3、5×5领域),再为每个局部区域计算“局部特征表征”,比如:这个小领域内像素的特征统计值(特征均值、方差)、纹理规律等,类同全局类别感知中的全局类别中心。
其判断逻辑为:一个像素的类别,更取决于它周围相邻像素的共性特征,比如在遥感图像的“城市区域”中,某像素周围全是“低矮建筑”的纹理特征,那它更可能是“建筑”;若周围是“稀释植被+裸土”,则更可能归为“未利用地”,而非单依赖全图“建筑”的统一均值。
针对性解决遥感图像痛点
(1)局部异类区域的分类模糊,比如农田边缘常夹杂“道路”、“水渠”,全图“农田”均值会把水渠误判为农田,但局部类别感知会发现“水渠区域的领域像素是光滑的、线性的水体特征”,从而正确分类。
(2)小目标与背景粘连的干扰,比如遥感图像中的“电线杆”,全图“电线杆”的全局均值可能被大面积“道路”背景掩盖,将其误分类为道路上的一个小斑点,局部类别感知会聚焦“电线杆周围像素的细长、垂直特征”,避免把电线杆和道路混为一谈。
(3)同一类别在局部的细微差异,比如“森林”中,有的局部是“针叶林”(暗绿色、纹理密集),有的是“阔叶林”(亮绿色、纹理稀疏),全局均值会将二者统称为“森林”,但局部类别感知能捕捉到局部纹理差异,实现更精确的“亚类分类”。
局部类别感知,即以全图其中的一个patch,即以一个像素为中心的一定区域的领域为主体,以此提取局部更加细节的特征,弥补全局类别感知对细节的丢失。
1 引言
1翻译
遥感图像语义分割旨在为图像中地理空间对象的每个像素分配明确的类别。该技术在环境保护 [1]、资源调查 [2]、城市规划 [3,4] 等领域具有广泛应用。近年来,遥感平台与传感器的快速发展使得遥感图像的空间分辨率、光谱分辨率和时间分辨率不断提高 [5],这为精细观测地球表面特征提供了可能。因此,为满足处理海量数据的需求,更先进的遥感图像语义分割技术不断涌现 [6,7]。
与自然图像相比,遥感图像语义分割面临更大挑战,主要原因如下:
- 背景复杂:遥感图像语义分割的目标是分割建筑物、道路、河流等地理空间对象。这些对象在不同场景中通常具有多样的形状、分布和位置(如图 1 所示),极其复杂的场景会导致大量误检。
- 类内差异大:对于同一类别的对象(如建筑物、道路、农田),由于其尺寸、形状、颜色、光照条件乃至成像条件的差异,提取的语义特征存在较大差异。此外,复杂背景进一步增大了类内差异,而类内差异大不利于语义类别的识别。
- 尺度与方向多变:自然图像中的对象受重力影响,通常朝向一致且尺度差异较小。然而,由于遥感图像采用俯视视角且成像范围大,图像中的对象往往具有不同朝向,且尺度差异显著。因此,遥感图像分割需要专门的上下文建模技术来应对这种尺度与方向变化。
本文致力于设计一种高效的网络结构来解决上述问题。首先,我们对基于卷积的神经网络进行分析。现有的基于卷积神经网络(Convolutional Neural Network, CNN)的语义分割方法主要关注上下文建模 [8-12],可分为空间上下文建模和关系上下文建模两类。空间上下文建模方法(如 PSPNet [8]、DeepLabv3+[13])采用空间金字塔池化(Spatial Pyramid Pooling, SPP)或空洞空间金字塔池化(Atrous Spatial Pyramid Pooling, ASPP)来整合空间上下文信息。尽管这些方法能捕捉同类上下文依赖关系,但忽略了类别间的差异,在处理具有复杂特征和大光谱差异的遥感图像时,可能会产生不可靠的上下文信息。
关系上下文建模方法基于注意力机制捕捉异类依赖关系。非局部神经网络 [9] 通过计算图像内像素对的相似度进行加权聚合;DANet [10] 则利用空间注意力和通道注意力进行选择性聚合。然而,这类密集注意力操作并不适用于遥感图像,因为复杂的背景会导致这些操作产生大量背景噪声,从而降低语义分割性能。
近年来提出的类别级上下文建模方法(如 ACFNet [14]、OCRNet [15]、CCENet [16]、HMANet [17])通过利用全局类别表征整合类别级上下文(即类别中心),能够减少密集注意力带来的背景噪声干扰,但在遥感图像上的表现仍不理想。这是因为遥感图像类内差异大,导致特征与全局类别中心之间存在较大语义差距,进而影响模型性能。
因此,我们将目光转向基于 Transformer 的方法 [18-22]。由于其核心组件是空间自注意力,在处理遥感图像时同样面临大量背景噪声干扰的问题,导致在大多数遥感数据集上性能较差。特别是,空间自注意力操作的二次计算复杂度使其在处理高分辨率遥感图像时,会产生巨大的计算成本和内存消耗。更重要的是,上述所有方法都忽略了遥感图像的关键属性 —— 尺度与方向变化。因此,有必要开发一种能够针对遥感图像这些特征的模型,以提升分割性能。
本文提出了一种新颖的局部 – 全局类别感知网络 LOGCAN++,该网络包含两个关键组件:全局类别感知(GCA)模块和局部类别感知(LCA)模块。GCA 模块参考了已有研究 [14,15] 的设计思路,通过提取全局类别中心进行类别级上下文建模,减少背景噪声干扰。同时,LCA 模块旨在缓解类内差异问题,创新性地将局部类别中心作为中间感知单元,间接将像素与全局类别中心关联起来。特别地,在局部类别中心提取过程中,我们引入了仿射变换块(Affine Transform Block, ATB),该模块通过仿射变换函数将默认的局部窗口转换为目标四边形,从而使局部窗口的大小、形状和位置能够适应不同的地理空间对象。这样,ATB 生成的局部类别中心基于对象内容,能够很好地应对遥感图像中的尺度与方向变化。
本文的主要贡献总结如下:
- 设计了一种新颖的局部 – 全局类别感知策略,通过将局部类别中心作为中间感知单元,间接将像素与全局类别中心关联,有效缓解了遥感图像中的类内差异问题。
- 首次引入仿射变换块用于提取局部类别中心,以适应不同尺寸、形状和朝向的地理空间对象,从而很好地应对遥感图像的尺度与方向变化。
- 提出了专为遥感图像特征设计的语义分割模型 LOGCAN++。在三个遥感图像语义分割基准数据集上的大量实验结果表明,LOGCAN++ 优于其他最先进的方法,并且在精度与效率之间实现了更好的平衡。
本文是我们之前会议论文 [23] 的扩展版本,主要在以下三个方面对前期工作进行了拓展:
标准化实验设置并补充了充分的实验:新增了在更大规模 LoveDA 数据集上的实验,同时提供了更多的定量对比结果、定性分析和消融实验,通过更充分的实验数据验证 LOGCAN++ 的有效性。
引入仿射变换改进 LCA 模块,通过将默认局部窗口转换为目标四边形,适应不同尺寸、形状和朝向的地理空间对象,从而更好地应对遥感图像的尺度与方向变化。
将 LCA 模块中的注意力操作扩展为多头注意力,以提升模型捕捉复杂像素 – 类别中心关系的能力,并避免单一注意力机制可能导致的过拟合问题。
1、现有的基于卷积神经网络的语义分割方法主要关注上下文建模(空间上下文建模、关系上下文建模)。
2、空间y下文建模常用的方法有:使用空间金字塔池化(Spatial Pyramid Pooling, SPP)或空洞空间金字塔池化(Atrous Spatial Pyramid Pooling, ASPP)来整合空间上下文信息。虽然这种方法能够捕捉同类上下文依赖关系,但忽略了不同类别间的差异,在处理具有复杂特征和大光谱差异的遥感图像时,可能会产生不靠谱的上下文关系。
(比如同一幅图中既有茂密森林、裸露土壤,又有金属屋顶的工厂、蓝色的湖泊,若模型不考虑不同类别之间的差异,就可能把本不属于同一类的区域错误关联:比如将 “工厂金属屋顶的高反射特征”,错误和 “湖泊的高反射特征” 归为一类并建立上下文关系,最终生成 “把工厂误判为湖泊” 这类不可靠的上下文信息,导致分割结果出错。)
3、关系上下文建模方法基于注意力机制捕捉异类依赖关系。非局部神经网络通过计算图像内像素对的相似度进行加权融合;DANet则利用空间注意力和通道注意力进行选择性聚合。然而这类密集注意力操作不适用与遥感图像,这是由于遥感图像的复杂背景导致这些操作产生大量背景噪声,从而影响语义分割性能。
其中背景噪声包括:由遥感设备本身或信号传输过程产生的、是成像时的“固有干扰”的:热噪声、量子噪声、条带噪声、传输噪声;由成像时的外部环境因素导致、与地物所在的自然or人工场景有相关的:大气噪声、阴影噪声、人工噪声;源于地物自身的复杂特征,属于伪目标干扰,容易让模型混淆有效类别的:混合像元噪声、地物变异噪声。
4、由于遥感图像的类内差异较大的问题,近年来提出的类别级上下文建模方法虽然可以减少关系上下文建模操作带来的背景噪声干扰,但结果仍不理想。
5、基于Transformer的方法在处理遥感图像时也同样面临着大量背景噪声的干扰。
6、同时上述方法也忽略掉了遥感图像的尺度、方向等变化的属性,这同样也会影响模型的性能。
7、本文提出的局部-全局类别感知网络LOGCAN++,包含两个关键组件:全局类别感知模块(GCA)、局部类别感知模块(LCA),其中GCA模块旨在通过提取全局类别中心进行类别级上下文建模,减少背景噪声干扰,LCA模块旨在缓解遥感图像的类内差异的问题,将局部类别中心作为中间感知单元,间接地将像素与全局类别中心关联起来。
空间上下文建模
空间上下文建模的核心,就是让模型在分析遥感图像时,不止看单个像素或孤立的局部patch,还能“关联”其周围相邻区块的特征,通过捕捉像素与像素、patch与patch之间的空间关系(比如:某像素旁边是道路,上方是建筑,通过这种信息来修正对该像素的分类),以此修正单个区域的判断偏差,解决“只看局部导致的误判”问题。
其本质就是模拟人类的“联想判断”,就像我们看到“一片绿色区域旁边有农田垄沟”,会结合这个“空间上下文信息”判断它是农田,而非孤立地看到绿色就误判为“森林”等。
总结来说就是让模型从“单看某个像素点的特征去判断像素的类别”升级为“看一片区域之间的关系等信息去判断像素的类别”。
关系上下文建模
关系上下文建模的核心,就是让模型在分析遥感图像时,不止关注像素或区域的自身特征,更能捕捉“不同类别、不同区域之间的关联规则”(比如:农田常与水渠相邻、机场跑道必然连接停机坪),通过这些“关系逻辑”修正分割偏差,解决“只看特征相似性、忽略类别关联性导致的误判”的问题。
其本质就是让模型像人类一样能够“理解场景逻辑”,就像我们知道“烟囱不会独立存在,必然连接着某个建筑物”,即使烟囱像素特征与路灯相似,也能通过上述的场景逻辑的关系准确对其分类。
总结来说,关系上下文建模的价值,是让模型从“单个某个区域的特征”升级为“看类别间的存在关系逻辑”,通过学习不同场景下的“类别关联”、场景约束、层级包含等规则,解决特征相似类别的区分难题,修正不符合现实逻辑的分割结果,让遥感图像不仅特征对,更逻辑对。
2 相关工作
2.1 通用语义分割
翻译
语义分割本质上是图像分类的延伸,从对图像整体的分析扩展到对像素级的分析。传统语义分割方法通常为每个像素点设计手工特征描述符以进行特征提取,但设计特征描述符耗时耗力,且手工特征的鲁棒性较差,需要大量专家先验知识。全卷积网络(Fully Convolutional Network, FCN)[24] 创新性地提出了一种端到端的方法,专门用于处理像素级分类任务。然而,卷积网络有限的感受野成为了性能瓶颈。为解决这一问题,后续研究聚焦于上下文建模,旨在通过空间上下文建模和关系上下文建模扩大感受野、捕捉全局信息,从而提升特征表征能力。代表性工作包括 PSPNet [8]、DeepLab 系列 [25,26,27,13]、DenseASPP [28]、DMNet [29] 等。
为进一步增强关系上下文建模,近年来的研究 [10,30,31] 常基于注意力操作构建模型。Wang 等人 [9] 采用自注意力机制,使任意位置的单个特征都能感知其他所有位置的特征;Fu 等人 [10] 引入双重注意力机制,更好地捕捉特征间的关系,提升语义分割性能;Huang 等人 [11] 计算特征图行与列之间的交叉注意力,使每个位置都能感知其他位置的上下文信息,提高语义分割精度。
与在整个特征图上进行密集关系建模不同,部分研究 [14,15,32-34] 从类别角度进行上下文建模,通过计算像素与类别级上下文的相似度以及对类别级上下文进行加权聚合,提高类内紧致性。Zhang 等人 [14] 首次提出类别中心的概念,从类别角度提取全局上下文;Yuan 等人 [15] 提出对象上下文表征,通过计算每个像素与每个目标区域的关系,并将所有目标区域表征加权聚合为目标上下文表征,增强每个像素的表征能力;Jin 等人 [35] 提出分别聚合图像级和语义级上下文信息,以增强像素表征。
Transformer [36] 近年来在计算机视觉领域得到广泛应用 [37-41]。例如,ViT [42] 将输入图像划分为块,并将其转换为向量序列,但在处理大尺寸图像时效率较低,且不适用于图像分割等多尺度、密集预测任务。为解决这些问题,Swin Transformer [43] 引入窗口机制和多尺度设计,以克服这些局限性。在语义分割领域,Transformer 已通过 Segmenter [18] 对 ViT 的应用以及 SegFormer [19] 的无位置依赖多尺度编码策略得到有效应用。近年来,基于掩码分类的方法逐渐流行 [44-47],MaskFormer [44] 将语义分割转化为更通用的掩码分类任务,而 Mask2Former [21] 通过掩码注意力机制进一步提升了该方法的效率和性能。
综上所述,上述方法在自然图像上取得了显著成果,但应用于遥感图像时,由于忽略了遥感图像背景复杂、尺度与方向多变、类内差异大的特征,性能并不理想。例如,近期的通用分割方法(如 Segmenter [18]、DDP [48])虽然具有较多参数和较大计算量,但在遥感图像上的性能并未与其模型规模相匹配(详细数据见表 1、表 2 和表 3)。这促使我们提出 LOGCAN++,其网络结构专门针对遥感图像的这些特性进行设计。
1、传统语义分割基于为每个像素点手工设计特征,费时费力,且鲁棒性差。
2、FCN专门应用于像素级别分类的方法,但受限于卷积有限的感受野。
3、近年来基于Transformer搭建的模型算法,在处理大尺寸图像时效率较低,且不适用于图像分割等多尺度。密集预测任务。
4、Swin Transformer引入窗口机制和多尺度设计克服Transformer应用在语义分割的缺点;Segmenter对ViT的应用及SegFormer的无位置依赖多尺度编码策略;Mask2Former通过掩码注意力机制提示Transformer的效率和性能。
5、尽管Transformer在自然图像上取得显著成果,但面对遥感图像的三大典型特征,性能仍不理想。
2.2 遥感图像语义分割
翻译
遥感图像语义分割方法可分为两类技术路线:特定应用场景方法和通用应用场景方法。
前者与通用语义分割方法思路相似,但针对特定应用场景(如土地利用 / 土地覆盖(Land Use and Land Cover, LULC)分类 [49,3,50]、建筑物提取 [51,52,53]、道路提取 [54,55,56,57]、车辆检测 [58])进行改进。例如,Jung 等人 [51] 引入整体边缘检测(Holistic Edge Detection, HED),在结构化编码器上提取边缘特征,以增强遥感图像中建筑物边缘的清晰度;Bastani 等人 [57] 通过基于 CNN 的决策函数引导的迭代搜索过程,实现从 CNN 输出中直接生成道路网络图;Mou 等人 [58] 基于残差学习原理,从不同残差块中有效学习多级上下文特征表征;Luo 等人 [54] 结合 CNN 和 Transformer 技术,设计双向 Transformer 模块,有效捕捉全局和局部上下文信息。然而,这些方法主要聚焦于特定应用场景的改进,忽略了遥感图像目标分割中类内差异大、尺度与方向多变等共性问题,应用范围受限。
近年来,针对通用应用场景的分割模型(如 LANet [59]、MANet [60]、PointFlow [61]、SCO [62]、GLOTs [63]、FarSeg++[64])也得到了广泛研究。但这些方法仍未充分考虑遥感图像背景复杂、尺度与方向多变、类内差异大的特征,限制了模型性能的进一步提升。例如,Ding 等人 [59] 提出利用局部注意力块增强上下文信息嵌入,虽能缓解对象尺度变化和类内差异问题,但忽略了复杂背景带来的挑战;Zheng 等人 [64,65] 通过学习前景 – 场景关系来关联前景相关上下文,增强前景特征的区分度,尽管能很好地增强前景特征,但忽略了遥感图像中较大的类内差异,导致类内特征紧致性较差。特别是,这些方法对遥感图像尺度与方向多变的特征考虑不足。因此,由于结构设计上的缺陷,这些方法的性能仍有提升空间。
1、针对特定应用场景(如土地利用、土地覆盖等)的遥感图像语义分割的方法进行改进。
2、Jung等人引入整体边缘检测,增强遥感图像中建筑物边缘的清晰度;Bastani等人通过基于CNN的决策函数引导的迭代搜索过程,实现从CNN输出直接生成道路网状图;Mou基于残差学习原理,学习多级上下文特征表征;Luo等人基于Transformer,设计双向Transformer模块,捕捉全局、局部上下文信息。
3、2中的方法主要聚焦于特定场景的改进,却忽略了遥感图像目标分割中的三大典型特征,使模型应用范围受限。
4、针对通用应用场景的分割模型未充分考虑到遥感图像背景复杂、尺度与方向多变、类内差异大的特征,限制了模型的性能。
3 方法
3.1 整体架构
翻译
由于遥感图像通常存在背景复杂、尺度与方向多变、类内差异大的问题,我们提出了一种局部 – 全局类别感知网络 LOGCAN++ 来应对这些挑战。LOGCAN++ 的整体架构如图 2 所示,由骨干网络、一组局部类别感知(LCA)模块和一个全局类别感知(GCA)模块组成。
具体而言,首先将输入的高分辨率遥感图像 I 输入到骨干网络中,提取多尺度特征R1、R2、R3和R4(分别对应原始分辨率的 1/4、1/8、1/16 和 1/32)。其中,最深层特征R4被输入到 GCA 模块中,以获取全局类别中心Cg。随后,将特征R4与全局类别中心Cg一同输入到 LCA 模块中进行类别级上下文建模。得到的上下文增强输出特征Ro4与浅层特征R3拼接后,再次输入到 LCA 模块中。该过程重复三次,得到增强后的多尺度特征Ro1、Ro2、Ro3和Ro4。最后,将增强后的特征沿通道维度拼接,并通过一个简单的 1×1 卷积得到最终的预测结果。下文将详细介绍 GCA 模块、LCA 模块和损失函数的具体细节。
整体架构:
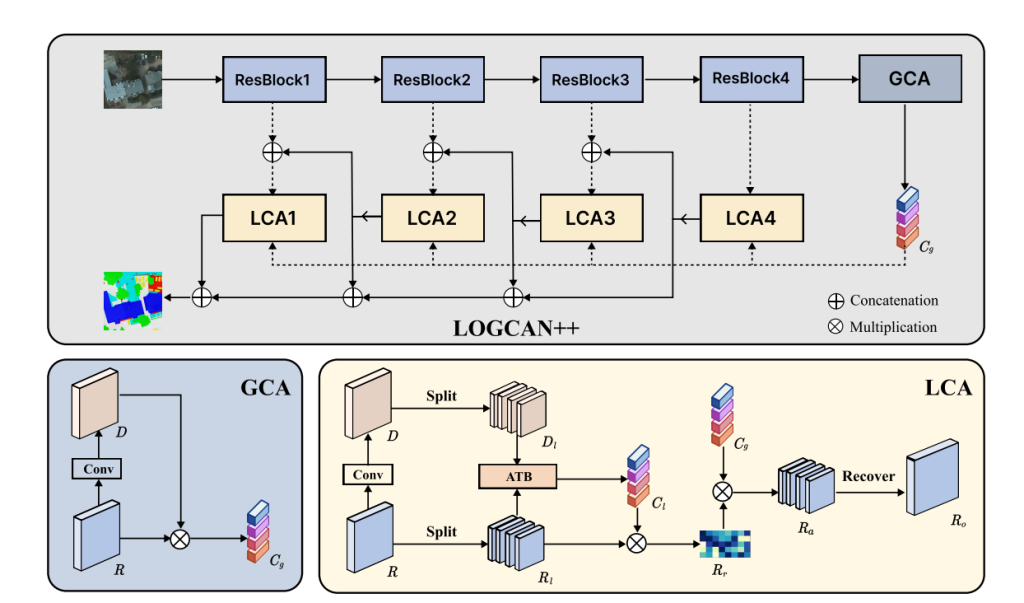
图2. 提出的LOGCAN++架构示意图,该架构由主干网络(默认采用ResNet-50)、局部类感知(LCA)模块和全局类感知(GCA)模块组成。GCA模块通过生成全局类中心来实现类别层面的上下文建模,从而降低背景噪声干扰。LCA模块基于仿射变换块(ATB)生成局部类中心,并将其作为中间感知元素,间接建立像素与全局类中心的关联以缓解类内差异。
1、局部-全局类别感知网络LOGCAN++:由主干网络、一组局部类别感知(LCA)模块与一个全局类别感知模块(GCA)组成。
2、主干特征提取路径:数据从左侧输入,依次经过四个残差块(ResBlock)进行特征提取,得到的特征最终送入GCA模块中;局部类别感知路径: 从四个残差块中提取不同层级的特征,被分别送入四个对应的LCA模块中;将LCA输出的特征与GCA输出的全局类别中心一同输入到LCA中,增强类别特征,以此类推,将增强后的特征通过通道维度拼接,并通过一个简单的 1×1 卷积得到最终的预测结果。
3、全局类别感知模块:接收网络最深层的特征,通过一系列操作(如:拆分、卷积、激活函数等),生成类别中心。
4、局部类别感知模块:对输入的特征图使用卷积处理之后得到一个深色特征图,分别进行分割操作,分成多组子特征图,将多组子特征图输入到ATB中进行仿射变换,将变换后的特征与输入特征分割后的特征进行融合,传入恢复模块,把多组子特征重新整合为完整的特征图,最终输出。
3.2 全局类别感知模块
翻译:

3.3 局部类别感知模块
翻译:
在遥感图像中,同一类别的对象(如建筑物)由于尺寸、形状、颜色、光照条件和成像条件的差异,提取的语义特征往往存在较大的类内差异。这种较大的类内差异给已有方法 [14,15] 的类别级上下文建模带来了另一个问题:特征与全局类别中心之间的语义距离过大,影响类别级上下文建模的准确性。考虑到局部范围内同一类别的对象往往具有较高的相似性,我们提出了一种有效的策略 —— 以局部类别中心作为中间感知单元,间接将像素与全局类别中心关联起来。


3.4 仿射变换块
翻译:
理想的局部类别中心应是局部区域内对象的平均语义特征。然而,由于卫星传感器独特的俯视视角和较大的成像范围,遥感图像中的对象通常具有不同朝向,且尺度差异显著。固定的局部窗口往往无法很好地对这些对象进行建模。因此,我们提出仿射变换块(Affine Transformation Block, ATB),用于提取更高质量的局部类别中心 —— 通过将固定局部窗口转换为目标四边形,以适应不同尺寸、形状和朝向的地理空间对象。

结构:
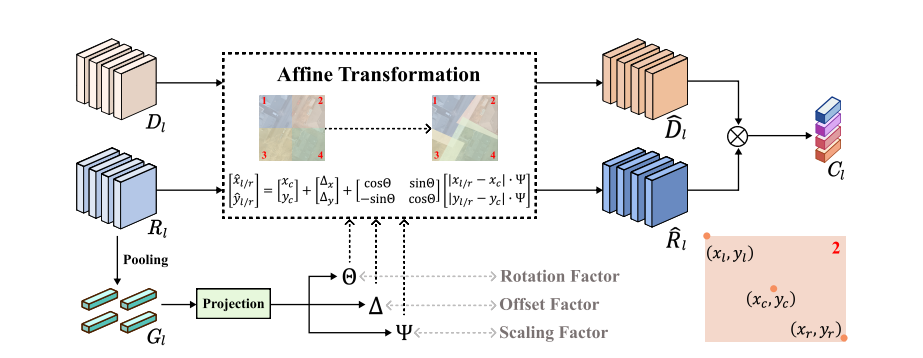
图3. 仿射变换块(ATB)的结构细节。 ATB首先对特征进行池化和投影处理,以生成缩放因子Ψ、偏移因子∆和旋转因子Θ。这些因子将默认的局部窗口转换为一个目标四边形,以适应不同尺寸、形状和方向的地理空间对象。因此,由ATB生成的局部类中心是数据依赖的,从而能很好地应对遥感图像中存在的尺度和方向变化。
1、为解决遥感图像方向与尺度多变的这一特征,固定的窗口无法很好地对这些对象建模,因此,本文提出ATB并嵌入LCA中(LCA是取整个对象中的其中的patch进行提取局部信息上下文),代替固定的窗口操作,转换为目标四边形,以适应遥感图像尺寸、形状和朝向多变的特征。
2、输入与预处理:输入两类特征图,浅色特征图与深色特征图,对深色特征图进行池化操作,得到低维特征,提取关键信息、减少计算量;变换参数生成:将池化后的低维特征图输入到Projection(投影)模块中,生成仿射变换的三个核心参数:Θ:旋转因子(Rotation Factor),控制图像旋转角度、Δ:偏移因子(Offset Factor),控制图像在横、纵方向的平移、Ψ:缩放因子(Scaling Factor),控制图像的放大或缩小;仿射变换执行:利用生成的三个核心参数,对输入特征进行仿射变换得到变换后的特征,根据相应公式实现图像的旋转、平移、缩放等几何变换;特征融合:将变换后的特征进行融合,最终得到输出特征。
3.5 损失函数
翻译:

4 实验设置
4.1 数据集
翻译
我们在三个公开的高分辨率遥感(Remote Sensing, RS)数据集上对所提方法进行评估,包括 ISPRS Vaihingen 数据集 [72]、ISPRS Potsdam 数据集 [72] 和 LoveDA 数据集 [73]。
Vaihingen 数据集
Vaihingen 数据集由国际摄影测量与遥感学会(International Society for Photogrammetry and Remote Sensing, ISPRS)于 2014 年发布,已成为高分辨率遥感图像语义分割领域广泛使用的基准数据集。该数据集包含德国 Vaihingen 地区的高分辨率航空影像,对六种土地覆盖类别进行了详细的人工标注,分别为:不透水面(Impervious surfaces)、建筑物(Buildings)、低矮植被(Low vegetation)、树木(Trees)、车辆(Cars)以及杂乱背景(Clutter/Background)。
数据集包含 33 幅真彩色正射影像(True Orthophoto, TOP),每幅影像的空间分辨率为 0.09 米 / 像素,宽度范围在 1887 至 3816 像素之间。为评估分割性能,我们选取 ID 为 1、3、5、7、11、13、15、17、21、23、26、28、30、32、34、37 的影像用于训练,其余 14 幅影像用于测试。我们将 TOP 影像分割为 512×512 像素的图像块,且采用 512 像素的步长,以优化处理与分析效率。
Potsdam 数据集
Potsdam 数据集同样是高分辨率遥感图像语义分割系统开发与评估的常用数据集,其数据结构与 Vaihingen 数据集相似。该数据集包含 38 幅高质量影像块,每幅影像的地面采样距离(Ground Sample Distance, GSD)为 5 厘米,分辨率为 6000×6000 像素。数据集涵盖多个光谱波段(红、绿、蓝、近红外)、数字表面模型(Digital Surface Model, DSM)以及归一化数字表面模型(Normalized Digital Surface Model, NDSM)。在本实验中,我们主要关注红、绿、蓝三个波段。
参考 Vaihingen 数据集的划分方式,研究人员通常选取 ID 为 2_10、2_11、2_12、3_10、3_11、3_12、4_10、4_11、4_12、5_10、5_11、5_12、6_7、6_8、6_9、6_10、6_11、6_12、7_7、7_8、7_9、7_11、7_12 的影像块用于训练,其余 14 幅影像块用于测试。
LoveDA 数据集
LoveDA 数据集于 2021 年发布,是一个面向高分辨率遥感图像语义分割的综合数据集,以复杂背景、多样对象尺度和多变类别分布为显著特点。该数据集包含 5987 幅影像,每幅影像分辨率为 1024×1024 像素,涵盖七个类别:建筑物(Building)、道路(Road)、水体(Water)、植被(Vegetation)、车辆(Car)、杂乱区域(Clutter)和背景(Background)。
数据集覆盖面积达 536.15 平方公里,地面采样距离为 0.3 米,包含中国南京、常州、武汉三座城市的城乡场景。由于存在多尺度对象和不一致的类别分布,该数据集具有较大挑战性。数据集的标准划分方式为:2522 幅影像用于训练,1669 幅用于验证,1796 幅用于测试。
1、使用ISPRS Vaihingen、Potsdam、LoveDA数据集,对本文提出的模型及组件进行实验验证。
4.2 评估指标
翻译:

1、评价指标:MIoU、mAcc、F1分数
4.3 实现细节
翻译
为保证对比公平性,我们选用 ResNet-50 [74] 作为骨干网络 [59,64]。在训练设置方面,输入图像分辨率为 512×512 像素,批大小(batch size)设为 8。采用随机梯度下降(Stochastic Gradient Descent, SGD)优化器,初始学习率为 0.01,动量为 0.9,权重衰减为 0.0005。训练过程共进行 80000 次迭代,并采用多项式学习率策略。
为提升模型的泛化能力,我们采用了多种数据增强技术,包括随机翻转、缩放(缩放范围为 0.5-1.5)和光度失真。测试阶段采用多尺度增强策略,具体包括图像缩放(缩放范围为 0.5-1.5)和随机翻转。
所有实验代码基于 PyTorch 框架实现,运行环境为配备 48GB 显存的 NVIDIA A6000 显卡,操作系统为 Linux Ubuntu 20.04。
1、主干网络使用ResNet-50,图像分辨率为512×512像素,批量大小设置为8,优化器采用随机梯度下降(SGD),初始学习率为 0.01,动量为 0.9,权重衰减为 0.0005。训练过程共进行 80000 次迭代,并采用多项式学习率策略。
2、数据增强处理:随机翻转、缩放、光度失真以提高模型泛化能力。测试阶段采用多尺度增强策略,具体包括图像缩放(缩放范围为 0.5-1.5)和随机翻转。
3、源码基于PyTorch,GPU为48GB显存的NVIDIA A6000显卡(8GB的NVIDIA 4060怕是带不动吧..)
5 实验结果与分析
5.1 ISPRS Vaihingen 数据集上的结果
5.1.1 定量分析
翻译
为验证 LOGCAN++ 的有效性,我们首先在 Vaihingen 数据集上开展实验。对比方法包括基于卷积的方法(如 PSPNet [8]、DeepLabV3+[13]、Semantic FPN [67]、DANet [10]、OCRNet [15]、FarSeg [65])、基于 Transformer 的方法(如 Segmenter [18]、DC-Swin [68]、UnetFormer [20]、EfficientViT [69])以及基于扩散模型的方法(如 DDP [48])。
如表 1 所示,LOGCAN++ 取得了最优的分割性能。具体而言,与近期的通用分割方法(如 DDP)和遥感分割方法(如 UnetFormer)相比,我们的方法在 mIoU 指标上分别提升了 2.05% 和 1.23%。特别地,对于建筑物这类类内差异较大的类别,我们的方法实现了 91.85% 的 mIoU 值,优于其他主流方法,验证了局部 – 全局类别感知策略的有效性。此外,针对车辆这类小目标,我们的方法相较于 DDP 在 mIoU 上提升了 1.82%,这表明仿射变换的引入增强了对小目标的细粒度识别能力。
此外,与近年来一系列主流方法相比,LOGCAN++ 还具备良好的效率优势。具体而言,若移除 GCA 模块并改用局部类别中心,模型参数会减少 0.1M,计算量(FLOPs)会减少 0.01G;若移除 LCA 模块并改用全局类别中心,模型参数会减少 2.06M,计算量会减少 10.744G。这些结果表明,LCA 和 GCA 模块的设计具有轻量化特性。
与当前最先进的方法 DDP 相比,LOGCAN++ 的参数仅为 DDP 的 78%,计算量仅为 DDP 的 21%,但性能更优(F1 分数达 84.22)。与轻量化方法 UnetFormer 和 EfficientViT 相比,LOGCAN++ 的效率相当或略有优势,同时性能显著提升,在 F1 指标上分别提高了 1.52 和 7.78。综上,所提 LOGCAN++ 在精度与效率之间实现了更好的平衡。
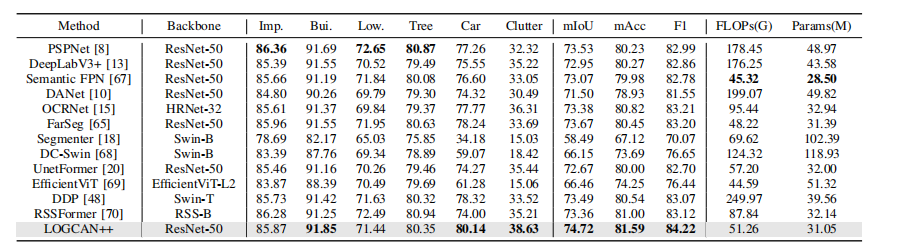
表 1 在 ISPRS Vaihingen 数据集的测试集上与最先进方法的对比。每类的最佳性能用粗体标记。FLOPS(浮点运算次数)是在尺寸为 512×512×3 的情况下计算的。
1、LOGCAN++取得最优分割性能。
2、LCA与GCA模块的设计具有轻量化特性。
3、与当前最先进的方法DDP相比,LOGCAN++参数量与计算量都较小,并且性能更优。与轻量化方法UNetformer、EfficientViT相比,LOGCAN++效率相当,并且性能更优。
4、综上,LOGCAN++在精度与效率之间实现了更好的平衡。
5.1.2 定性分析
翻译
为探究 LOGCAN++ 对像素特征生成过程的影响,图 4 可视化了 Vaihingen 测试集影像的特征分布。具体而言,我们采用 t-SNE [71] 方法,对 FarSeg、UnetFormer 和 LOGCAN++ 最后一层输出的特征进行可视化。可以观察到,FarSeg 和 UnetFormer 提取的不透水面与建筑物类别的特征分布存在交叉重叠,而 LOGCAN++ 提取的这两类特征具有良好的分离度。此外,对于建筑物类别,LOGCAN++ 提取的特征更为紧致。
这一现象可归因于:我们提出的局部 – 全局类别感知策略有效缓解了类内差异问题,并实现了与全局类别中心的更优交互,从而提取出更具区分性的特征。综上,与 FarSeg 和 UnetFormer 相比,LOGCAN++ 提取的特征具有更高的类内紧致性和类间分离度。
此外,图 5 可视化了不同模型输出的分割掩码,以定性对比 LOGCAN++ 与其他竞争方法的分割性能(所有输入影像均来自 Vaihingen 测试集)。具体而言,对于第一幅输入影像,UnetFormer [20] 和 EfficientViT [69] 在建筑物类别的掩码边界上存在模糊问题;对于第二幅输入影像,FarSeg [65] 在建筑物类别掩码上出现碎片化现象(部分像素被误分类为不透水面)。
相比之下,LOGCAN++ 输出的掩码中,两幅影像的建筑物均具有更完整的形状和更清晰的边界。对于第三幅影像,LOGCAN++ 能够准确识别车辆,而 UnetFormer 和 DDP [48] 等方法会将车辆误分类为建筑物。此外,LOGCAN++ 对低矮植被区域的分割完整,而 FarSeg 由于低矮植被与不透水面的光谱和形状极为相似,出现了部分像素误分类为不透水面的情况。这些结果表明,LOGCAN++ 具有更优的语义识别能力和可视化效果。
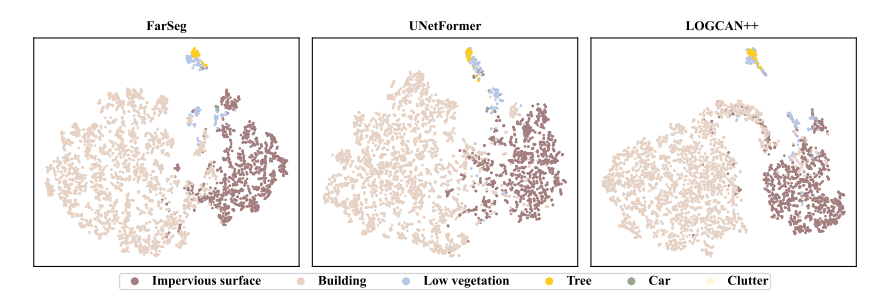
图 4. FarSeg、UNetFormer 和 LOGCAN++ 最后一层输出特征的可视化。测试图像选自 ISPRS Vaihingen 数据集。我们使用 t-SNE [71] 进行了该实验。

图5. LOGCAN++与其他最先进方法在Vaihingen测试集上的定性比较。红色虚线框是重点关注区域。建议在彩色模式下查看并放大查看效果最佳。
1、为探究LOGCAN++对像素特征生成过程的影响,对FarSeg、UnetFormer 和 LOGCAN++最后一层输出的特征进行可视化。
2、提出的局部 – 全局类别感知策略有效缓解了类内差异问题,并实现了与全局类别中心的更优交互,从而提取出更具区分性的特征。因此LOGCAN++提取的特征具有更高的类内紧致性和类间分离度。
5.2 ISPRS Potsdam 数据集上的结果
5.2.1 定量分析
翻译
我们同样在 Potsdam 数据集上开展实验,以验证 LOGCAN++ 的有效性。如表 2 所示,LOGCAN++ 显著优于所有其他最先进方法,具有明显优势。具体而言,与 EfficientViT 和 DDP 等近期分割方法相比,我们的方法在 mIoU 指标上分别提升了 5.20% 和 0.81%。
特别地,Potsdam 数据集上呈现出与 Vaihingen 数据集相似的现象:对于建筑物、不透水面这类类内差异较大的类别,LOGCAN++ 分别实现了 93.76% 和 87.51% 的 mIoU 值;对于车辆这类小目标,LOGCAN++ 的 mIoU 达 93.13%,远优于其他方法。这进一步验证了:通过局部 – 全局类别感知策略和仿射变换,LOGCAN++ 能够有效应对遥感图像背景复杂、尺度与方向多变、类内差异大等挑战。
5.2.2 定性分析
翻译
类似地,图 6 可视化了 Potsdam 测试集影像的特征分布。对于不透水面、树木等类别,LOGCAN++ 提取的特征具有更优的类内紧致性。我们认为,原因在于俯视视角下的不透水面和树木通常形状不规则,且尺度与方向变化频繁,而 LOGCAN++ 基于仿射变换,能够缓解上述现象导致的类内特征差异过大问题。此外,LOGCAN++ 不同类别间的特征分布交叉更少。这些定性结果表明,LOGCAN++ 能够获取更高质量的语义特征。
此外,我们还可视化了 LOGCAN++ 与其他竞争方法输出的分割掩码。如图 7 所示,第一幅影像中,LOGCAN++ 能够保留更清晰的建筑物边界;第二幅影像中,LOGCAN++ 能够在复杂背景下识别出低矮植被;第三幅影像中,LOGCAN++ 显著减少了复杂背景导致的误检。这些结果表明,得益于其结构设计的有效性,LOGCAN++ 能够显著提升分割掩码的质量。
5.3 LoveDA 数据集上的结果
5.3.1 定量分析
翻译
表 3 对比了 LoveDA 数据集上的实验结果。显然,LOGCAN++ 在 LoveDA 数据集上大幅优于其他最先进方法。与 EfficientViT 和 DDP 等近期分割方法相比,我们的方法在 mIoU 指标上分别提升了 6.23% 和 0.81%。此外,LOGCAN++ 在建筑物、荒地等易混淆类别上的性能提升尤为明显。
需要注意的是,与 Vaihingen 和 Potsdam 数据集相比,LoveDA 数据集的背景更复杂、样本量更大,且地理场景差异显著(如城市与乡村)[73]。因此,可合理得出结论:LOGCAN++ 的有效设计使其在更具挑战性的分割场景中仍能持续取得优异性能。
5.3.2 定性分析
翻译
图 8 可视化了 LoveDA 验证集影像的分割掩码。对于第一幅影像中的农田类别,其他对比方法会将其误分类为建筑物或水体,而 LOGCAN++ 能够识别出正确的语义类别。尽管其掩码形状并非完全完整,但我们的方法已展现出更优的类别识别能力,这可归因于 LOGCAN++ 基于局部 – 全局类别感知策略,增强了特征的区分性。
此外,对于第二幅和第三幅影像,LOGCAN++ 分割出的形状更完整,而对比方法的掩码往往存在碎片化问题。这些优异的可视化结果进一步验证了 LOGCAN++ 在遥感图像语义分割任务中的有效性。
5.4 消融实验
翻译
为进一步验证模型设计的有效性,我们在 Vaihingen 数据集上开展了一系列消融实验。总体而言,我们针对模型结构、仿射变换块(ATB)设计、局部块数量以及多头注意力的头数进行了消融分析。这些实验与分析为确定最优模型设计提供了依据,下文将详细阐述。
5.4.1 模型结构分析
翻译:

5.4.2 全局类别中心Cg生成方式分析
翻译
表 5 对比了使用骨干网络不同层生成的特征图(分辨率不同)进行预分类并推导全局类别中心时的模型性能。结果表明,当模型使用最深层特征图时,性能达到峰值,尤其在车辆等小目标上的性能提升显著。我们认为,最深层特征图能有效滤除大量噪声干扰,使模型聚焦于小目标的关键信息,从而提升识别能力。
5.4.3 ATB 设计分析
翻译:

5.4.4 局部块数量分析
翻译:

5.4.5 注意力头数分析
翻译:

6 结论
翻译
本文首先详细分析了遥感图像的特征(即背景复杂、尺度与方向多变、类内差异大)。在此背景下,我们提出了高度定制化的 LOGCAN++,以应对上述特征带来的分割挑战。具体而言,LOGCAN++ 基于局部 – 全局类别感知策略,减少背景噪声干扰并缓解类内差异问题。特别地,由于在局部类别中心提取过程中引入了仿射变换,LOGCAN++ 能够很好地适应遥感图像中的尺度与方向变化。
在三个遥感语义分割数据集上的实验结果表明,LOGCAN++ 显著优于其他最先进方法,且在精度与效率之间实现了更好的平衡。在未来的工作中,我们将进一步探索将其与现有语义分割宏模型(如 SAM)相结合,以充分发挥 LOGCAN++ 在遥感图像分割领域的潜力。
1、高度定制化LOGCAN++模型能够应对遥感图像的三大典型特征。
2、在三个遥感语义分割数据集上的实验表明,LOGCAN++显著优于其他最先进方法,在精度与效率之间实现了更好的平衡。
3、进一步探究:将其现有语义分割宏模型(如SAM)相结合。