基于从头训练Transformer的遥感图像变化检测
发布期刊IEEE TGRS
发布日期2024.4.4
核心团队:穆罕默德・本・扎耶德人工智能大学(MBZUAI)
0 摘要
翻译
当前基于 Transformer 的变化检测(CD)方法要么采用在大规模图像分类 ImageNet 数据集上预训练的模型,要么依赖先在其他变化检测数据集上预训练,再在目标基准数据集上微调。这种现有策略的核心原因在于,Transformer 通常需要大量训练数据来学习归纳偏置,而标准变化检测数据集规模较小,难以满足这一需求。本文提出一种端到端的基于 Transformer 的变化检测方法,该方法无需预训练,从零开始训练,却在五个基准数据集上实现了最先进的性能。不同于传统自注意力机制在从零训练时难以捕捉归纳偏置的问题,本文架构采用了一种打乱稀疏注意力(shuffled sparse-attention)操作,通过聚焦选定的稀疏信息区域,捕捉变化检测数据的固有特征。此外,本文引入变化增强特征融合(CEFF)模块,通过逐通道重加权实现输入图像对特征的融合。该 CEFF 模块有助于增强相关语义变化,同时抑制噪声干扰。在五个变化检测数据集上的大量实验验证了所提方法的优势,与文献中已发表的最佳结果相比,交并比(IoU)得分提升高达 1.35%。代码已开源:https://github.com/mustansarfiaz/ScratchFormer。
1、动机
- 现有基于 Transformer 的变化检测(CD)方法依赖预训练(ImageNet 或其他 CD 数据集),从零训练时因难以捕捉归纳偏置导致性能不佳,而标准 CD 数据集规模小,无法满足 Transformer 对大量训练数据的需求。
- 传统自注意力机制操作均匀采样的密集块,难以聚焦遥感图像中与 CD 任务相关的稀疏信息区域,且计算复杂度高、收敛慢。
- 现有方法的特征融合多采用简单的差分、求和或拼接,未进行显式通道重加权,难以有效增强语义变化、抑制噪声干扰。
2、成果
- 设计分层 Transformer 孪生双流框架,无需预训练直接从零训练,在 5 个 CD 基准数据集(LEVIR-CD、DSIFN-CD 等)上均实现最先进(SOTA)性能。
- 打乱稀疏注意力(SSA):通过数据依赖的稀疏采样聚焦关键信息区域,降低计算复杂度,解决从零训练时归纳偏置捕捉难题。
- 变化增强特征融合(CEFF):通过逐通道重加权融合双流特征,增强语义变化特征、抑制噪声,提升变化检测精度。
代码已开源
Transformer孪生双流框架体现在:
- 框架包含两个完全相同的 Transformer 编码器流,分别处理“变化前图像” 和“变化后图像”,且两流共享所有参数。
- 编码器分为 4 个阶段(通道数 64→128→320→512,空间分辨率逐步下采样),每个阶段的 Transformer 层数量递增(3→3→9→3):浅层聚焦低层级特征(如边缘、纹理),深层聚焦高层语义特征(如建筑、变化区域)。
1 引言
翻译
变化检测(CD)是遥感领域的核心研究问题,旨在识别配准后的不同时间戳卫星图像之间的所有相关变化。变化检测在各类遥感应用中发挥着关键作用,包括灾害管理 [1]、城市规划 [2]、林业与生态系统监测 [3]、[4] 等。变化检测任务的目标是检测人造设施(如建筑物及其他构筑物)的相关语义变化,同时忽略噪声变化(如阴影、光照变化以及各类季节和环境变化)。图 1 展示了双时相卫星图像中变化检测任务面临的若干挑战。例如,图 1-(a) 和 (b) 中的树木、阴影及车辆可能会限制检测性能;同样,图 1-(c) 所示,光照变化和环境条件可能影响物体颜色;图 1-(d) 中,由于尺度变化和密集建筑区域的存在,精确检测细微和大范围变化区域成为一项艰巨任务;最后,图 1-(e) 突出了天气条件带来的挑战,这类因素可能会影响变化检测性能。因此,提取有意义的特征表示并忽略无关信息,对于变化检测任务至关重要。
通常,基于卷积神经网络(CNN)的变化检测方法通过利用扩张卷积、通道注意力和空间注意力等显式机制,取得了良好的效果。Zhang 等人 [5] 采用基于空洞卷积的 CNN 获取密集特征表示;DASNet [6] 结合扩张卷积与标准卷积提取局部特征表示,并应用双注意力机制进一步增强这些特征;部分方法 [7]、[8] 利用标准卷积与池化层提取多尺度深度特征;STANet [9] 采用标准 CNN 网络进行深度特征提取,并通过空间和时间注意力模块优化特征表示。然而,这类基于 CNN 的方法通常难以捕捉不同图像区域之间的长距离依赖关系,从而影响变化检测性能。
近年来,基于 Transformer 的变化检测方法 [10]、[11]、[12]、[13]、[14]、[15]、[16] 通过自注意力机制 [17] 对均匀采样的密集补丁之间的长距离依赖关系进行建模,在多个变化检测数据集上展现出具有竞争力的性能。尽管基于 Transformer 的方法取得了更优的变化检测性能,但最先进的相关方法 [10] 通常需要基于预训练的权重初始化以实现最优收敛。现有基于 Transformer 的变化检测方法的预训练步骤,要么基于其他变化检测数据集 [10],要么采用在 ImageNet 上预训练的图像分类模型 [16]、[11]、[12]、[18]、[14]。此外,已有研究提出多种基于孪生网络的监督对比预训练方法来处理过拟合问题,但随机初始化缺乏任何先验变化检测知识 [19]、[20]。Zhang 等人 [21] 研究了不同的度量学习方法,并针对变化检测任务提出时空三元组损失(STTL)。然而,当直接在目标变化检测数据集上从零开始训练时,这些基于 Transformer 的变化检测方法的性能会大幅下降。这可能是由于这些方法中采用的密集自注意力操作,其计算复杂度与令牌数量呈二次关系,不仅收敛速度慢,还容易发生过拟合。本文致力于设计一种基于 Transformer 的变化检测方法,该方法在从零开始训练的情况下仍能实现高性能。
大多数现有基于 Transformer 的变化检测方法采用双流架构,通过差分、求和和拼接等简单操作融合两个流的特征 [22]、[10]。然而,这些方法并未在两个流之间采用任何显式的特征重加权机制。本文认为,此类简单的特征融合策略难以有效聚合每个流中的语义变化。因此,本文旨在通过单一基于 Transformer 的变化检测架构,综合解决上述问题。
本文提出一种基于 Transformer 的孪生双流变化检测框架,名为 ScratchFormer。该框架基于一种新颖的打乱稀疏注意力(SSA)操作,能够更好地关注与变化检测任务相关的稀疏信息区域。所提 SSA 通过对基于数据依赖特征采样得到的打乱特征的稀疏子集进行令牌混合,使得模型直接在目标变化检测数据集上从零开始训练时,仍能实现最优的变化检测性能。此外,本文引入变化增强特征融合模块(CEFF),该模块基于逐通道校准进行特征融合,增强与语义变化相关的特征,同时抑制噪声特征。本文在五个公开变化检测数据集(LEVIR-CD [9]、DSIFN-CD [7]、WHU-CD [23]、CDD-CD [24] 和 OSCD [25])上进行了大量实验。所提 ScratchFormer 方法优于基线模型,凸显了所提创新点的有效性。与基线模型相比,ScratchFormer 在 CDD-CD 数据集上的交并比(IoU)绝对提升了 1.35%。此外,ScratchFormer 在所有五个数据集上均刷新了最先进性能。在 LEVIR-CD 数据集上,ScratchFormer 的 IoU 得分为 84.63%,比文献中最新方法 [10] 高出 2.15%。图 2 展示了最新的 ChangeFormer [10] 与本文 ScratchFormer 在不同复杂变化检测案例中的定性对比。
本文的贡献总结如下:
- 提出一种分层 Transformer 孪生双流变化检测算法(ScratchFormer),该算法无需在其他变化检测数据集上预训练,直接从零开始训练,却能实现最先进性能,省去了在其他变化检测数据集上预训练后再在目标基准数据集上微调的步骤。
- 提出打乱稀疏注意力(SSA),该注意力机制利用变化检测任务中的稀疏信息区域。所提 SSA 操作通过对基于数据依赖特征采样得到的打乱特征的稀疏子集进行令牌混合。
- 提出变化增强特征融合模块(CEFF),该模块用于突出语义特征,同时忽略噪声特征。
- 在五个变化检测数据集上的大量实验验证了所提算法的优势。与基于 CNN、Transformer 和混合架构的变化检测方法相比,本文算法展现出最先进的性能。
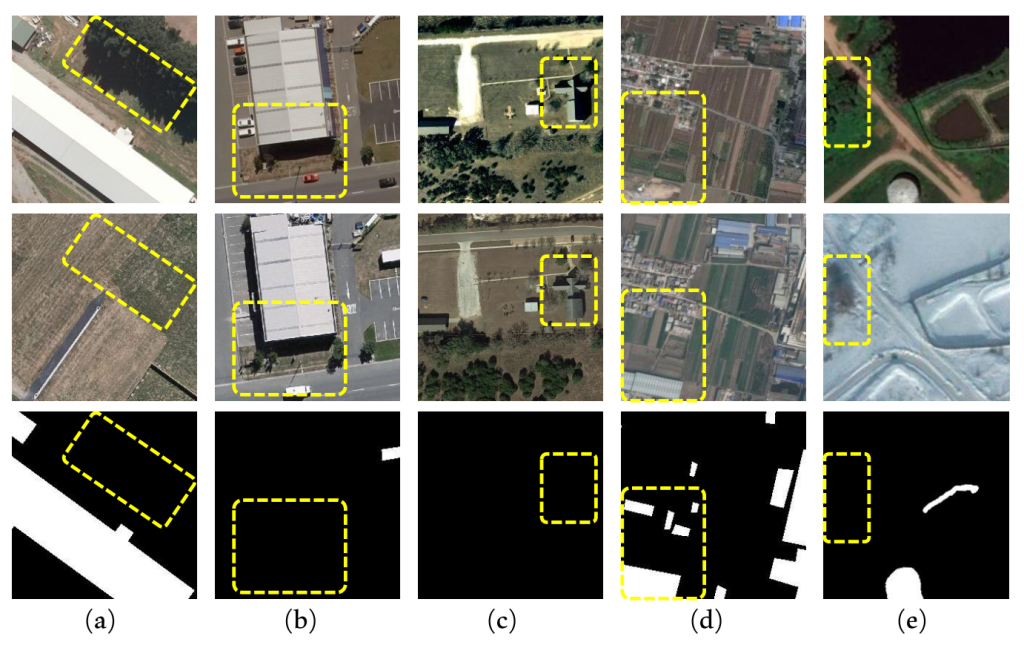
图 1 该图展示了卫星图像中变化检测任务面临的各类挑战,包括(a)树木及其阴影、(b)车辆及阴影方向、(c)光照变化、(d)分散的细微和大范围语义变化区域以及(e)季节性条件。第一行、第二行和第三行分别表示变化前图像、变化后图像和真实标签图像。
2 相关工作
翻译
由于卷积神经网络(CNN)具有捕捉判别特征的固有特性,其在遥感变化检测领域备受青睐 [18]。Chen 等人 [6] 在孪生 CNN 中引入双注意力机制,以编码长距离依赖关系。该孪生 CNN 模块用于从图像对中提取局部特征,随后利用双注意力模块获取全局上下文特征,从而更好地分离变化区域和未变化区域。Fang 等人 [26] 提出密集孪生网络,用于从双时相图像中提取特征,并采用集成通道注意力模块在多个语义层级优化和聚合特征。该模块旨在抑制语义间隙,减少变化区域的定位误差。文献 [27] 提出一种带注意力机制的特征金字塔,用于编码长距离依赖关系。作者采用 VGG16 [28] 网络作为骨干特征提取器,随后利用协同注意力模块聚合低层级和高层级特征,以获得更优的检测结果。Liu 等人 [29] 通过对抗学习,利用多尺度卷积注意力特征学习双时相特征差异。作者采用由生成器和判别器组成的超分辨率模块,通过对抗学习学习低分辨率图像与高分辨率图像之间的映射关系,随后利用堆叠注意力模块在多尺度层级增强判别特征。Hou 等人 [30] 采用低秩分析,以充分利用深度特征进行变化检测。Xu 等人 [31] 提出 MFPNet,该网络为变化检测任务引入通道注意力机制。同样,Wang 等人 [32] 利用空间注意力和通道注意力改善特征表示。RaSRNet [33] 引入基于图的关系感知机制,以解决 CNN 在变化检测任务中感受野受限的问题。Chen 等人 [9] 提出基于孪生网络的架构,利用空间注意力和通道注意力捕捉时空依赖关系。Zhang 等人 [7] 提出一种深度监督图像融合网络用于变化检测,该网络采用基于孪生网络的 CNN 从双时相图像中提取特征,并将提取的特征输入差异判别网络,通过深度监督获得变化检测掩码。
近年来,Transformer [17] 在变化检测任务中受到广泛关注 [34]。Chen 等人 [16] 提出双时相图像 Transformer(BIT),用于建模上下文信息。BIT 采用 ResNet18 [35] 从遥感图像对中提取特征,将提取的特征转换为一组语义令牌,并通过 Transformer 编码器建模令牌特征集之间的上下文关系,随后利用孪生 Transformer 解码器将编码后的特征投影回空间域,最后通过浅层 CNN 模块预测变化掩码。Li 等人 [11] 提出 TransUNetCD,该网络结合 Transformer 和 UNet 的优势用于变化检测。TransUNetCD 采用 CNN 从双时相图像中提取特征,随后利用 Transformer 获取更优的判别特征以完成变化检测任务。Zhou 等人 [36] 利用自注意力机制建模输入双时相图像之间的上下文 – 语义关系。Zhao 等人 [37] 提出位置匹配机制(PMM),利用地理空间位置和内容推理机制(CRM)对多时相图像进行稀疏像素级自适应匹配,以区分各类伪变化信息。Hu 等人 [38] 采用无监督联合学习模型,该模型结合总变差正则化和二分 CNN。Fang 等人 [39] 提出孪生网络,用于计算多层特征,并对双流进行特征交换操作以完成变化检测任务。
Zhang 等人 [40] 利用分层 Swin Transformer [41] 提取双时相图像中的全局信息。Song 等人 [12] 采用多尺度 Swin Transformer,在多尺度层级增强基于孪生网络的 CNN 提取的特征。Wang 等人 [42] 提出 STCN,该网络利用交叉 Swin Transformer 提取全局特征。Teng 等人 [43] 引入 SFCD,该方法通过前景感知融合模块,利用注意力门修剪低层级特征响应,从而改善特征表示。Hong 等人 [44] 将多任务网络集成到 Swin Transformer 中,利用可用训练样本进行代表性特征学习。Ke 等人 [14] 提出混合 Transformer,用于在多尺度捕捉全局上下文依赖关系。在 CNN 骨干网络提取特征后,利用所提混合 Transformer 学习全局上下文关系,随后将其输入级联解码器进行变化图预测。Bandara 等人 [10] 提出分层孪生 Transformer,用于生成多尺度特征。该孪生编码器利用自注意力和卷积层学习判别特征。与现有方法不同,本文引入 SSA,使得模型在任何变化检测(目标)数据集上从零开始训练时,仍能有效捕捉变化检测的归纳偏置。此外,本文提出 CEFF 模块,通过逐通道重加权增强具有较高语义变化的特征通道,同时抑制编码噪声变化的通道。
3 前言
3.1 问题定义

翻译
给定配准后的卫星图像对 \(I_{pre}\)、\(I_{post} \in \mathbb{R}^{3×H×W}\)(分别在不同时间 \(T_1\) 和 \(T_2\) 采集),变化检测的目标是检测 \(I_{pre}\) 和 \(I_{post}\) 之间的相关语义变化,同时忽略无关变化。其中,相关变化包括人造设施(如建筑物及其他构筑物)的变化;无关变化包括季节变化、光照变化、建筑物阴影和大气变化等。因此,变化检测的目标是预测二值掩码 \(M \in \mathbb{R}^{H×W}\),该掩码用于描述 \(I_{pre}\) 和 \(I_{post}\) 之间的语义(结构)变化。
3.2 基线变化检测框架

翻译
本文采用最新提出的基于 Transformer 的方法 [10] 作为基线框架,该方法在变化检测任务中取得了良好的性能。该基线变化检测框架以图像对作为输入,通过基于 Transformer 的孪生网络计算图像对之间的语义差异。该框架包括 Transformer 编码器、差异特征融合模块和解码器。编码器由一系列注意力层组成,每个注意力层包含标准自注意力 [17] 和前馈网络。编码器权重共享,用于计算双流(变化前和变化后)的多尺度特征。对于每个尺度 i,双流的输出特征 \(F_{pre}^i\)、\(F_{post}^i\) 输入差异特征融合模块,该模块对对应尺度下双流之间的语义变化进行编码。差异特征融合模块包括特征拼接操作,随后是两个卷积层,卷积层之间设有批量归一化和 ReLU 层,并输出尺度 i 的特征 \(F_{diff}^i\)。这些多尺度特征 \(F_{diff}^i\) 随后输入解码器,通过一系列卷积和转置卷积层融合,以提高特征图的空间分辨率。最后,将上采样后的特征输入掩码预测层,得到最终的语义二值变化图 M。
3.3 局限性
翻译
如前所述,基线框架采用带有标准自注意力机制的 Transformer 编码器,以捕捉图像中的长距离依赖关系。本文认为,标准自注意力机制在变化检测任务中并非最优,主要原因如下:标准自注意力机制作用于均匀采样的密集补丁,因此需要大量训练数据才能在变化检测性能方面实现最优收敛(见图 3)。最新的 ChangeFormer [10] 通过在一个(源)变化检测数据集上预训练,然后在另一个(目标)变化检测数据集上微调,缓解了这一问题。然而,这增加了训练时间(需包含在其他变化检测数据集上的预训练成本)。此外,尽管所提 ScratchFormer 从零开始训练,但与在其他变化检测数据集上预训练后微调的基线模型相比,ScratchFormer 的精度更高,且训练时间缩短了不到 50%。
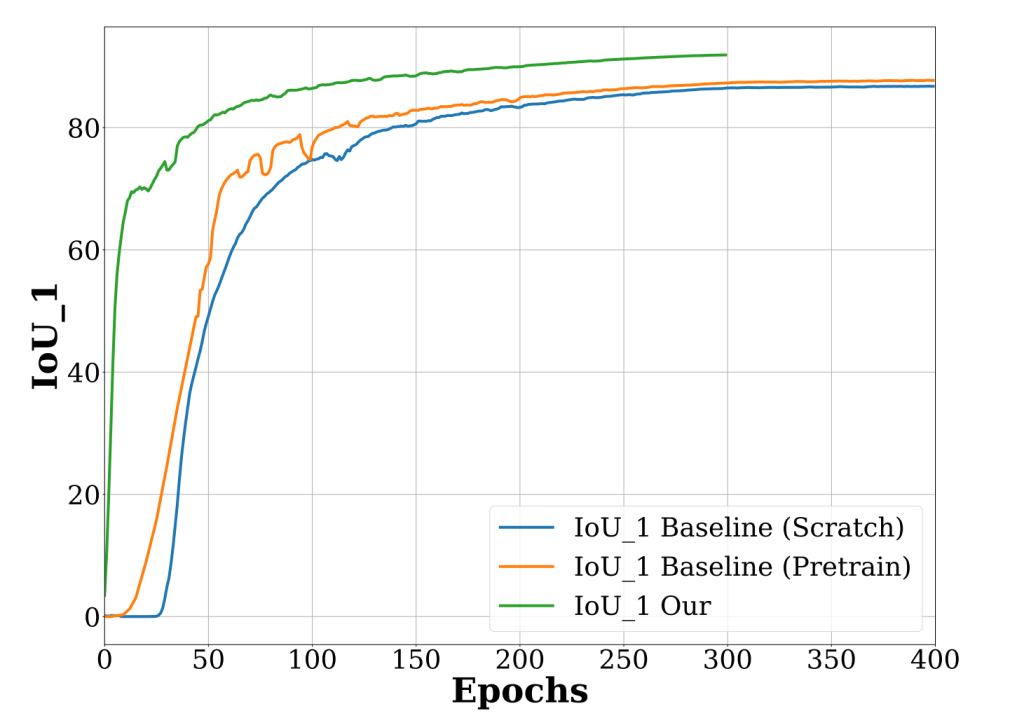
图 3 在 LEVIR-CD 数据集上,从零训练的基线方法、先在其他变化检测数据集上预训练然后微调的基线方法与本文方法在交并比(IoU)和训练轮次方面的对比。与预训练的基线方法相比,从零训练的基线方法在变化检测性能方面的收敛性较差。尽管本文方法是从零训练的,但与两种基线方法相比,本文方法在变化检测性能方面的收敛性更优。例如,本文方法仅需不到 50% 的训练时间,就能达到与从零训练的基线方法最终结果相当的变化检测性能。
4 方法
4.1 研究动机
翻译
为了推动所提方法的发展,本文明确了设计基于 Transformer 的变化检测方法时特别需要具备的两个特性:
语义变化增强特征融合:尽管上述要求侧重于设计关注变化检测任务中稀疏信息区域的机制,但第二个理想特性旨在捕捉图像对之间的语义差异,同时忽略无关噪声变化。为此,变化增强特征融合模块通过显式建模变化前和变化后图像之间的逐通道相互依赖关系,有望更好地忽略噪声变化,同时保留相关变化。接下来,本文将介绍所提基于 Transformer 的 ScratchFormer 框架。
变化检测任务的注意力机制重新设计:如前所述,当直接在目标变化检测数据集上从零开始训练时,传统自注意力机制可能导致性能不佳,这可能是由于在小规模变化检测数据集上难以捕捉固有的归纳偏置。此外,标准自注意力机制通常作用于均匀采样的密集补丁,而遥感场景中存在稀疏信息区域,这些补丁可能难以学习丰富的特征表示,以编码具有不一致外观的多样形状物体。因此,需要重新设计自注意力机制,通过关注遥感变化检测图像中的稀疏信息区域,有效学习丰富的特征表示。
1、设计基于Transformer的变化检测任务方法时特别需要具备的两个特性:
- 语义变化增强特征融合旨在捕捉图像对之间的语义差异,同时忽略无关噪声变化,具体操作:显示建模变化前和变化之后图像之间的逐通道相互依赖关系,更好地忽略噪声变化的同时保留相关变化。
- 变化检测任务的注意力机制重新设计重新设计自注意力机制,通过关注遥感变化检测图像中的稀疏信息区域,有效学习丰富的特征表示。
4.2 整体架构

翻译
图 4 展示了 ScratchFormer 的整体架构。所提 ScratchFormer 以变化前和变化后图像对(\(I_{pre}\)、\(I_{post}\))作为输入,包括基于孪生网络的编码器、变化增强特征融合模块和用于预测二值变化图M的解码器。编码器在四个阶段计算不同空间分辨率的特征。在每个阶段,首先通过卷积层对特征进行空间下采样,然后输入到 SSA 层。ScratchFormer 包括两个并行的相同编码器流,权重共享,分别在多级网络的第i阶段生成变化前和变化后特征\(\hat{F}_{pre}^i\)、\(\hat{F}_{post}^i\)。本文设计的核心是在编码器中引入一种新颖的打乱稀疏注意力层,对基于数据依赖的特征子集执行自注意力操作,以有效捕捉变化检测任务的语义变化。此外,本文提出变化增强特征融合模块,该模块对双流同一尺度的特征(\(\hat{F}_{pre}^i\)和\(\hat{F}_{post}^i\))进行逐通道校准,并执行增强特征融合,以更好地忽略噪声变化,同时保留相关变化。
图 4 ScratchFormer 变化检测框架的整体架构。ScratchFormer 以变化前和变化后图像对作为输入,并预测对应图像对的二值语义变化图。ScratchFormer 包括基于孪生网络的分层编码器(四个不同阶段)、变化增强特征融合(CEFF)模块和用于预测二值变化图的解码器。本文设计的核心是在编码器中引入打乱稀疏注意力(SSA)层(第四节 C 部分)和变化增强特征融合(CEFF)模块(第四节 D 部分)。如(a)所示,SSA 层包括打乱稀疏注意力和 MLP。SSA 在每个阶段对基于数据依赖的特征稀疏子集进行令牌混合。ScratchFormer 方法在不同尺度i下,通过双流计算 SSA 特征\(\hat{F}_{pre}^i\)和\(\hat{F}_{post}^i\)。如(b)所示,这些阶段的输出通过 CEFF 模块融合。CEFF 模块通过在每个尺度执行逐通道重加权,增强双流特征之间的语义变化,并输出增强特征\(\hat{F}_{enh}^i\)。然后,这些增强特征输入到解码器中,用于预测最终的语义二值变化图M。
如 4(a)所示,SSA 层包括打乱稀疏注意力和多层感知器(MLP)。SSA 首先对特征进行基于数据依赖的采样,得到子集,然后对选定的子集进行令牌混合。SSA 通过关注变化检测的稀疏信息区域,无需在其他变化检测数据集上预训练,就能实现变化检测性能的最优收敛。CEFF 模块旨在增强编码器每个阶段变化前和变化后特征之间的语义变化,同时抑制噪声变化。CEFF 模块的输出增强特征调整到相同的空间分辨率,然后输入到解码器中。解码器包括一系列卷积、转置卷积和上采样层,以提高特征图的空间分辨率。因此,这些上采样特征输入到掩码预测层,以获得最终的二值掩码M。为了更好地理解整体框架,本文还给出了算法 1。接下来,本文将介绍 SSA 层。
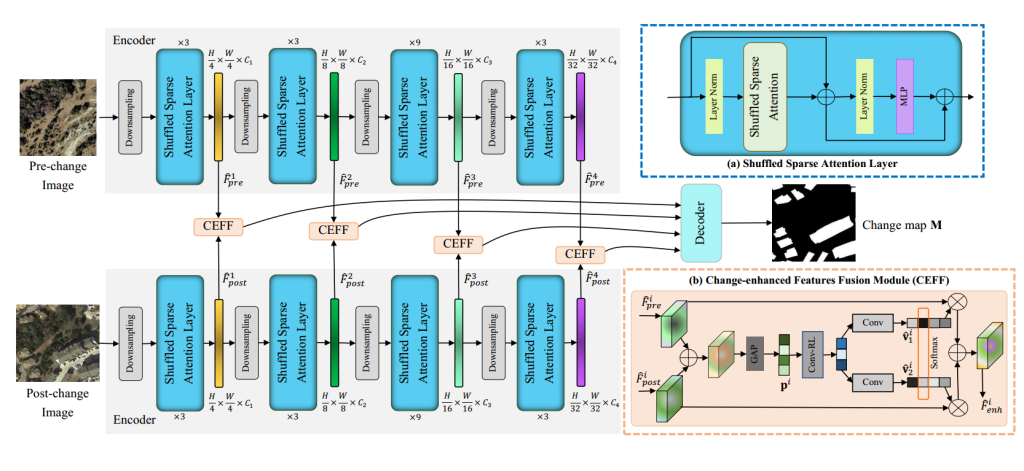
图4 ScratchFormer架构图
1、ScratchFormer流程
- 输入与编码器部分包含两个输入,一个是变化前图像(Pre-change images)的输入以及变化后图像(Post-change-image)的输入,这一对配准的遥感图像;数据输入到网络后进入编码器结构部分,编码器架构采用孪生双流共享权重的分层编码器,每个阶段先对输入图像进行下采样(downsampling),逐步降低空间分配率(从H/4×W/4到H/32×W/32),提升通道数,每个阶段经过下采样之后接入打乱稀疏注意力层(Shuffled Sparse Attention Layer)(每个阶段重复次数为3、3、9、3),输出对应阶段的特征输入到该阶段对应的CEFF模块中。
- 核心模块细节
- 打乱稀疏注意力层(SSA)其结构图如图中a部分,是编码器的核心组件。输入的特征首先经过层归一化(稳对输入特征进行通道维度的归一化,稳定特征的数值分布(避免不同通道特征的均值、方差差异过大),让后续注意力操作的梯度更稳定,加快模型训练的收敛速度。),然后执行打乱稀疏注意力操作(聚焦数据依赖的稀疏信息区域),将操作之后的特征与模块原始输入特征进行残差连接之后,再经过层归一化和多层感知机MLP,最终输出该层的特征,该模块的主要作用就是降低计算复杂度的同时,捕捉变化检测任务的关键特征,支撑“从零训练”的高性能。
- 变化增强特征融合模块(CEFF)其结构图如图中b部分,用于融合同一阶段“变化前与变化后”的特征。因此,该模块的输入是模块所在对应阶段的两个时相的图像特征,首先将两特征进行求和操作得到两时相初步融合的特征,对该特征经过全局平均池化(GAP)后得到全局特征向量,再通过Conv-ReLU-Conv得到两个通道权重,经过softmax归一化之后,与模块原始输入特征逐通道加权融合,最终求和得到增强后的融合特征。该模块的主要作用就是:增强语义变化特征,抑制噪声干燥。
- 解码器与输出每个阶段经过变化增强特征融合CEFF模块处理后得到的增强特征都输入到解码器中,通过上采样等操作恢复空间分辨率,最终输出变化检测图,标识两幅图像的语义变化区域。
2、变化增强融合CEFF模块中,得到两个通道权重的组件不太一样,最后得到的两个通道权重也不同,具体见4.4节
3、打乱稀疏注意力操作见4.3
4.3 打乱稀疏注意力层


翻译
本文在编码器中引入打乱稀疏注意力层,以捕捉输入图像对\(I_{pre}\)和\(I_{post}\)之间的语义变化。
如 4(a)所示,该层包括打乱稀疏注意力、多层感知器和层归一化层。SSA 对基于数据依赖采样策略选择的特征稀疏子集进行令牌混合。设\(F^i \in \mathbb{R}^{C^i×H^i×W^i}\)为输入到 SSA 的第i阶段编码器特征。
然后,SSA 的计算分为两个步骤。首先,对输入特征进行基于数据依赖的稀疏子采样,稀疏因子为\(\gamma\),得到特征子集\(\bar{F}_{kl}^i\)。然后,分别对这些\(\gamma^2\)个特征子集\(\bar{F}_{kl}^i\)执行自注意力操作,其中\(k=\{0,…, \gamma-1\}\),\(l=\{0,…, \gamma-1\}\)。特征的基于数据依赖的稀疏空间子采样过程如下:
\(\forall \overline{x}=\left\{0, …, \frac{H^{i}}{\gamma}-1\right\} and \forall \overline{y}=\left\{0, …, \frac{W^{i}}{\gamma}-1\right\}. (1)\)
\(\Delta x=\Delta z(\gamma \overline{x}+k, \gamma \overline{y}+l, 1)\)
其中,\((\Delta x, \Delta y)\)表示基于数据依赖的位置偏移,这些偏移通过可学习参数offset预测得到,即\(\Delta z=\theta_{offset}(F^i)\)[45]。预测的偏移\(\Delta z \in \mathbb{R}^{2×H’×W’}\)包含两个通道,分别表示每个像素的水平和垂直位置偏移,对这些偏移进行裁剪,以限制与当前特征位置的最大距离。然后,位置偏移\(\Delta x\)、\(\Delta y\)计算如下:
\(\hat{F}_{kl}^i=Attention\left(\overline{F}_{kl}^i\right)\)
基于得到的稀疏采样特征\(\bar{F}_{kl}^i\),计算\(\gamma^2\)个稀疏窗口上的自注意力 [17](Attention (・)),如下所示:
\(p^{i}=G A P\left(\hat{F}_{p r e}^{i}+\hat{F}_{post }^{i}\right), (3)\)
然后,将\(\gamma^2\)个特征子集的注意力特征\(\hat{F}_{kl}^i\)打乱回原始分辨率特征图,得到\(\hat{F}^i \in \mathbb{R}^{C^i×H^i×W^i}\)。其中,基于数据依赖的位置偏移有助于自适应地从可能存在语义变化的区域采样密集特征,而稀疏采样有助于高效地保持全局感受野。为了更好地理解,本文在图 5 中给出了基于数据依赖的打乱稀疏特征采样的计算流程图。由于采用稀疏采样,本文执行\(\gamma^2\)个自注意力操作,每个自注意力操作中的令牌数量减少\(\gamma^2\)倍,从而使整体计算量减少\(O(\gamma^2)\)。由于 SSA 的稀疏结构允许自注意力聚焦于子采样的相关特征,因此所提 SSA 能够加快收敛速度。所提 ScratchFormer 方法在编码器的每个阶段采用 SSA 层,并通过编码器的双流计算变化前和变化后特征\(\hat{F}_{pre}^i\)、\(\hat{F}_{post}^i\)。然后,通过下文描述的变化增强特征融合模块融合这些特征。
图 5 公式 1 中所示的稀疏特征打乱示意图。将输入特征\(F^i\)输入到偏移计算层,生成基于数据依赖的位置偏移\(\Delta z\)。利用稀疏因子\(\gamma\)提取稀疏子采样特征。然后,利用计算得到的偏移获取打乱稀疏特征\(\hat{F}^i\)。
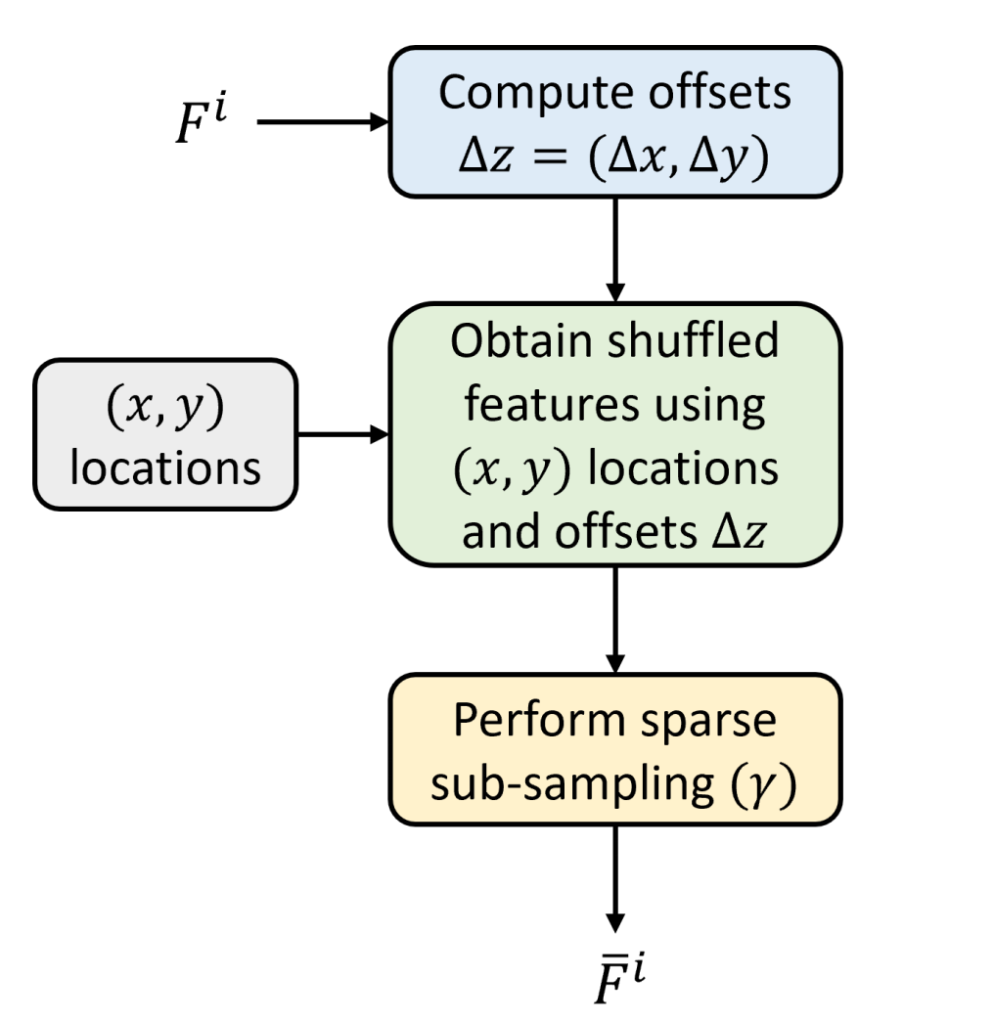

1、打乱稀疏注意力操作是一种融合 特征打乱 和 稀疏注意力 核心思想的优化项注意力机制
- 特征打乱是一种对特征的空间、通道、序列顺序进行重新排序的操作,其核心目的是打破特征的固有关联,强制模型学习更灵活的全局依赖,避免陷入局部最优。比如:在遥感图像中,变化前的的树木和变化后的阴影原本在固定空间位置相邻,特征打乱会将这些区域的特征块重新随机排序,让模型不再依赖固定位置关联去学习,而是主动捕捉跨区域的真实语义关联。此目的即是为了增强特征的多样性,提升模型的泛化能力,尤其在从零训练或小数据集场景下,能帮助模型更好地学习任务专属的归纳偏置。
- 稀疏注意力是对传统全自注意力的优化,核心是仅对特征中的任务相关的子集计算注意力,而非对所有特征对的关联,以此降低计算复杂度。即传统注意力需要计算所有特征单元token之间的关联,而稀疏注意力只计算关键特征单元比如局部邻域、数据依赖的重要区域的关联,降低了计算复杂度。常见的方法有:使用固定窗口稀疏,关注重点局部邻域;或使用数据依赖稀疏,通过偏移量定位关键区域后,仅对这些区域计算注意力。其作用就是在保证注意力效果的前提下,大幅降低计算、内存开销,适配高分辨率图像、长序列文本等场景。
- ps:总结两个优化的特点:特征打乱就是打破固有关联,增强全局依赖;稀疏注意力就是聚焦关键区域,降低计算复杂度
2、如图展示的是注意力操作前对特征进行稀疏打乱的流程,目标是从输入特征中提取数据依赖的稀疏打乱特征,为后续注意力操作做准备
- 输入与计算偏移量输入是SSA所在阶段对应的特征输入,进入打乱稀疏注意力操作层时,首先通过可学习的偏移预测层如卷积层,计算该特征对应的位置偏移量。其作用是基于特征本身的信息而非固定的窗口,定位 可能包含关键信息的区域(比如变化检测中的建筑变化区),实现数据依赖的动态采样。
- 获取打乱特征该步骤输入原始特征的空间位置,Locations(x, y),计算得到的偏移量,将原始位置与偏移量结合,从输入到打乱稀疏注意力操作的原始特征中提取对应位置的特征,并按新顺序重新排列这些特征,即打乱稀疏后的特征。其作用就是打破特征的固有空间关联,避免模型仅关注局部区域,强制模型学习跨区域的全局依赖,提升特征的多样性。
- 执行稀疏子采样preform sparse sub-sampling,该操作步骤输入是上一步得到的打乱特征,按稀疏因子对打乱后的特征进行子采样,只保留部分关键区域的特征,丢弃冗余与噪声区域的特征。其作用就是大幅降低后续注意力计算的复杂度,同时聚焦任务相关的核心信息。
- 输出稀疏打乱特征最终输出经过 偏移定位–>特征打乱–>稀疏采用 三个操作处理后的特征,该特征是聚焦关键区域、打破固有关联的精简特征,将其作为后续稀疏自注意力计算的输入。
- 这个子流程的核心是 动态定位关键区域+打乱特征+稀疏特征 的结合,即通过偏移量精准捕捉任务相关区域,又通过打乱增强特征的全局关联性,最后通过稀疏采样实现高效计算,为后续注意力操作提供高质量的输入特征。
4.4 变化增强特征融合模块




翻译
如前所述,在实际场景中,图像对中可能出现各种变化,因此在变化检测任务中,检测高级语义变化并忽略噪声变化是主要挑战之一。因此,需要有效融合编码器的变化前和变化后特征流的特征。在现有多种基于 Transformer 的变化检测方法 [10,16,46] 中,变化前和变化后特征之间的多尺度特征融合通过差分、求和或拼接操作实现。同样,基线框架也引入了一种差异模块,通过通道维度的拼接实现特征融合。本文认为,在每个阶段不对双流特征的通道进行显式重加权的情况下,融合双流特征对于变化检测任务并非最优。为此,本文引入 CEFF 模块,该模块通过逐通道重加权,增强具有较高语义变化的通道,同时抑制捕捉噪声变化的通道。图 4(b)展示了变化增强特征融合模块的结构。在编码器的所有四个阶段都引入了 CEFF 模块,以融合每个阶段的特征。
在 CEFF 模块中,首先通过求和操作融合变化前和变化后特征\(\hat{F}_{pre}^i\)、\(\hat{F}_{post}^i\),然后执行全局平均池化(GAP),得到全局特征向量\(p^i\),如下所示:
将特征向量\(p^i\)输入到共享的 Conv-ReLU 层,以减少通道数量。之后,将这些降维后的特征输入到独立的 1×1 卷积层,得到双流的通道权重\(v_1^i\)、\(v_2^i\),如下所示:
\(\begin{array}{r} \overline{p}^{i}=\varphi\left(\omega_{1}\left(p^{i}\right)\right), \\ v_{1}^{i}=\omega_{2}\left(\overline{p}^{i}\right), v_{2}^{i}=\omega_{3}\left(\overline{p}^{i}\right), \end{array}\)
其中,\(\omega_1\)、\(\omega_2\)和\(\omega_3\)是卷积权重,\(\varphi\)表示 ReLU 激活函数。其中,\(v_1^i \in \mathbb{R}^{C^i×1}\)和\(v_2^i \in \mathbb{R}^{C^i×1}\)表示第i阶段变化前和变化后特征的未归一化通道重加权因子。然后,通过双流的逐通道 softmax 对这些未归一化权重进行归一化,即:
\(\hat{v}_{1}^{i}(j)=\frac{exp \left(v_{1}^{i}(j)\right)}{exp \left(v_{1}^{i}(j)\right)+exp \left(v_{2}^{i}(j)\right)} \hat{v}_{2}^{i}(j)=\frac{exp \left(v_{2}^{i}(j)\right)}{exp \left(v_{1}^{i}(j)\right)+exp \left(v_{2}^{i}(j)\right)} (5)\)
其中,j是通道索引,exp表示指数函数。这些归一化权重\(\hat{v}_1^i \in \mathbb{R}^{C^i×1}\)和\(\hat{v}_2^i \in \mathbb{R}^{C^i×1}\)用于对\(\hat{F}_{pre}^i\)和\(\hat{F}_{post}^i\)进行通道重加权,然后通过求和操作进行特征融合,生成增强特征\(\hat{F}_{enh}^i\),如下所示:
\(\hat{F}_{enh}^{i}=\hat{v}_{1}^{i} \hat{F}_{pre}^{i}+\hat{v}_{2}^{i} \hat{F}_{post }^{i}, (6)\)
然后,将所有阶段 CEFF 模块的输出增强特征调整到固定的空间分辨率,并输入到解码器中,解码器执行特征上采样和变化图预测。
算法 1:计算变化前和变化后输入图像之间变化图的所提算法数据:两幅配准图像\(I_{pre}\)和\(I_{post}\)结果:变化图M
\(M \leftarrow Decoder(F_{all})\)
\(S \leftarrow stages = 4\);
\(B \leftarrow blocks = [3, 3, 9, 3]\)
对于\(j \in (pre, post)\):
对于\(i \leftarrow 1\)到S:
如果\(i == 1\):
\(I_{ij} \leftarrow I_j\) # 第 1 阶段的输入
否则:
\(I_{ij} \leftarrow \hat{F}_{i-1j}\) # 第 > 1 阶段的输入
\(t \leftarrow Downsampling(I_{ij})\)
重复:
# 打乱稀疏注意力(SSA)
\(\Delta z \leftarrow\) 计算t的偏移量 # 获取偏移量
\(\bar{t} \leftarrow\) 利用\(\Delta z\)获取稀疏采样特征(公式 1)
\(\hat{t} \leftarrow\) 计算\(\bar{t}\)的自注意力(公式 2)
\(t \leftarrow \hat{t}\)
直到\(B_i\);
\(\hat{F}_{ij} \leftarrow t\)
对于\(i \leftarrow 1\)到S:
# 变化增强特征融合(CEFF)
\(p_i \leftarrow\) 利用公式 3 计算\((\hat{F}_{ipre}, \hat{F}_{ipost})\)的全局向量
\((\hat{v}_{i1}, \hat{v}_{i2}) \leftarrow\) 利用\(p_i\)获取归一化权重(公式 4 和 5)
\(\hat{F}_{ienh} \leftarrow\) 利用公式 6 计算增强特征
\(F_{all} \leftarrow Concatenate(\hat{F}_{1enh}, \hat{F}_{2enh}, \hat{F}_{3enh}, \hat{F}_{4enh})\)
1、特征向量经过Conv-ReLU-Conv操作得到通道权重的过程并不完全相同:
- 全局特征向量先经过Conv-ReLU层,这一层是共用的,用于压缩通道数,提取基础特征,之后会分别进入两个独立的1×1卷积路径,分别对应两个不同的公式,在该卷积操作是不同的
- 由于两条路径的卷积层参数独立学习,最终输出的通道权重是分别针对变化前特征、变化后特征的专属权重,即通道权重1是增强或抑制变化前特征中语义变化通道的权重,通道权重2是增强抑制变化后特征中语义变化通道的权重
- 后续再经过softmax归一化后,两者会形成互补的权重分配,从而精准聚焦两时相特征的差异区域。
5 实验
5.1 实验设置

翻译
数据集:大规模 LEVIR-CD [9] 数据集用于建筑物变化检测。该数据集包含 637 对高分辨率(0.5 米 / 像素)图像对,这些图像对取自谷歌地球,尺寸为 1024×1024。在实验中,本文采用 256×256 的非重叠裁剪块,默认数据分割为训练集、验证集和测试集,分别包含 7120、1024 和 2048 个样本。DSIFN-CD [7] 数据集用于二值变化检测,包含来自中国六个城市的六对高分辨率(2 米)卫星图像对。本文采用该数据集的裁剪版本,图像尺寸为 256×256,训练集、验证集和测试集分别包含 14400、1360 和 28 个图像对。CDD-CD [24] 数据集包含 11 对季节性变化图像对,其中 7 对图像的尺寸为 4725×2700 像素,4 对图像的尺寸为 1900×1000 像素。将这些图像对裁剪为 256×256 的块,训练集、验证集和测试集的数据分割分别为 10000、3000 和 3000 个样本。WHU-CD [23] 数据集用于与建筑物相关的变化检测,包含一对高分辨率(0.075 米)图像对,尺寸为 32507×15354 像素。该航空数据集包含多种不同尺寸和颜色的建筑结构。该数据集还提供 256×256 像素的图像对,这些图像对具有非重叠区域,训练集、验证集和测试集的数据分割分别为 5947、743 和 744 个图像对。OSCD [25] 是一个公共变化检测数据集,侧重于城市变化。该数据集包含 24 对哨兵 2 号多光谱数据图像对,这些图像对取自卫星,也提供 RGB 格式。这些图像对来自世界不同地区。该数据集侧重于与建筑相关的变化,图像对的分辨率在 10 米到 30 米之间。本文将 RGB 图像裁剪为 256×256 尺寸,并采用随机旋转和翻转数据增强方法扩大数据集规模。
评估协议:遵循文献 [10],本文在所有数据集上采用变化类 F1 分数、变化类交并比(IoU)和总体精度(OA)评估变化检测结果。在这些评估指标中,变化类 IoU 是变化检测任务最具挑战性的指标。
实现细节:所提 ScratchFormer 以 256×256×3 的图像对作为输入,并在四个阶段计算双流特征,这四个阶段分别包含 3、3、9 和 3 个 SSA 层,输出通道数分别为 64、128、320 和 512。在所提 SSA 中,稀疏因子计算为\(\gamma=2^n\),其中\(n>0\)。采用逐像素交叉熵损失函数训练模型。在训练过程中,本文采用标准数据增强方法,包括随机尺度裁剪、高斯模糊、随机翻转和随机颜色抖动。在 4 个 NVIDIA A100 GPU 上,通过随机初始化训练网络。遵循文献 [10],采用 AdamW 优化器,权重衰减为 0.01,beta 值为 (0.9, 0.999)。批量大小设置为 16,初始学习率为 4.1e-4,训练 300 轮。在实验中,采用线性衰减策略,直到最后一轮降低学习率。通过沿通道维度的逐像素 argmax 操作计算二值变化掩码M。
1、在LEVIR-CD、DSIFN-CD、CDD-CD、WHU-CD、OSCD五个数据集上进行验证
2、评估指标:F1分数、交并比IoU、总体精度OA
3、模型的图像输入尺寸为256×256,这四个阶段分别包含 3、3、9 和 3 个 SSA 层,输出通道数分别为 64、128、320 和 512
4、在 4 个 NVIDIA A100 GPU 上,通过随机初始化训练网络
5、采用AdamW优化器,权重衰减为0.01,beta 值为(0.9, 0.999)。批量大小设置为16,初始学习率为4.1e-4,训练300轮
5.2 最先进方法对比
翻译
LEVIR-CD 数据集对比:表 1 展示了 LEVIR-CD 数据集上的最先进方法对比结果。在最新的基于 Transformer 的变化检测方法中,H-TransCD [14]、BIT [16]、ChangeFormer [10] 和 TransUNetCD [11] 的 IoU 分数分别为 81.92%、80.68%、82.48% 和 83.67%。所提 ScratchFormer 的 IoU 分数达到 84.63%,与最近发表的 ChangeFormer [10] 和 TransUNetCD [11] 相比,绝对提升分别为 2.15% 和 0.96%。
WHU-CD 数据集对比:表 1 展示了 WHU-CD 数据集上的最先进方法对比结果。在现有基于 Transformer 的方法中,BIT [16] 和 TransUNetCD [11] 的 IoU 分数分别为 72.39% 和 84.42%。相比之下,所提 ScratchFormer 通过在该数据集上随机初始化从零训练,取得了更优的性能,IoU 分数达到 84.97%。
CDD-CD 数据集对比:表 1 展示了 CDD-CD 数据集上的结果。在基于 CNN 的方法中,DASNet [6] 的 IoU 分数达到 86.39%。在基于 Transformer 的变化检测方法中,TransUNetCD [11] 通过采用改进的 ResNet50 骨干网络,IoU 分数达到 94.50%。相比之下,从零训练的所提 ScratchFormer 的 IoU 分数达到 95.85%。
DSIFN-CD 数据集对比:本文在 DSIFN-CD 数据集上,将所提方法与基于 CNN 和 Transformer 的最先进方法进行了对比。表 3 展示了对比结果。可以看出,最新的基于 Transformer 的方法取得了更优的 F1 分数。例如,BIT [16] 和 ChangeFormer [10] 的 F1 分数分别为 67.74% 和 69.50%。所提 ScratchFormer 优于这些最新方法,F1 分数达到 73.22%。值得注意的是,与 ChangeFormer [10] 相比,ScratchFormer 在 F1 和 IoU 方面的绝对提升分别为 3.72% 和 4.5%。值得一提的是,所提方法无需在其他变化检测数据集上预训练,直接从零训练。在该数据集上,ScratchFormer 刷新了最先进性能,在具有挑战性的指标上取得了显著提升。
OSCD 数据集对比:最后,表 5 展示了 OSCD 数据集上的结果。本文重现了 FC-Siam-Diff [8]、DTCDSCN [47]、BIT [16] 和 ChangeFormer [10] 的结果。在最新的最先进方法中,FC-Siam-Diff [8] 的 F1 分数最高,达到 56.01%。然而,从零训练的 ScratchFormer 的 F1 分数显著更高,达到 57.37%,刷新了最先进结果。
参数和时间对比:本文对比了 ScratchFormer 与其他基于 Transformer 骨干网络的方法在可训练参数、单图像对推理时间和模型每轮训练时间方面的差异。表 2 展示了基线方法具有更多参数和更长推理时间,且其 IoU 性能不如 ScratchFormer。此外,ChangeFormer [10] 的推理时间略短,但其可训练参数和训练时间高于所提方法。尽管所提方法的推理时间略长,但在所有指标上都取得了良好的结果,因此在性能和效率方面实现了更好的权衡。
定性对比:图 6 和图 7 分别展示了 LEVIR-CD [9] 和 WHU-CD [23] 示例中 ScratchFormer 与 BIT [16]、GeSANet [37] 和 ChangeFormer [10] 的定性对比结果。图 8 展示了 CDD-CD [24] 示例中 ScratchFormer 与基于 Transformer 的方法 [10,16,37] 的定性对比结果。此外,图 9 和图 10 分别展示了 DSIFN-CD [7] 和 OSCD [25] 数据集上 ScratchFormer 与 BIT [16]、GeSANet [37] 和 ChangeFormer [10] 的定性对比结果。结果表明,所提 ScratchFormer 能够检测复杂场景中多尺度的语义变化,直接在目标变化检测数据集上从零训练时仍能实现最优的变化检测性能。此外,这些定性分析证明了所提 ScratchFormer 的有效性,该方法利用新颖的打乱稀疏注意力,聚焦于稀疏信息区域,以捕捉变化检测数据的固有特征。
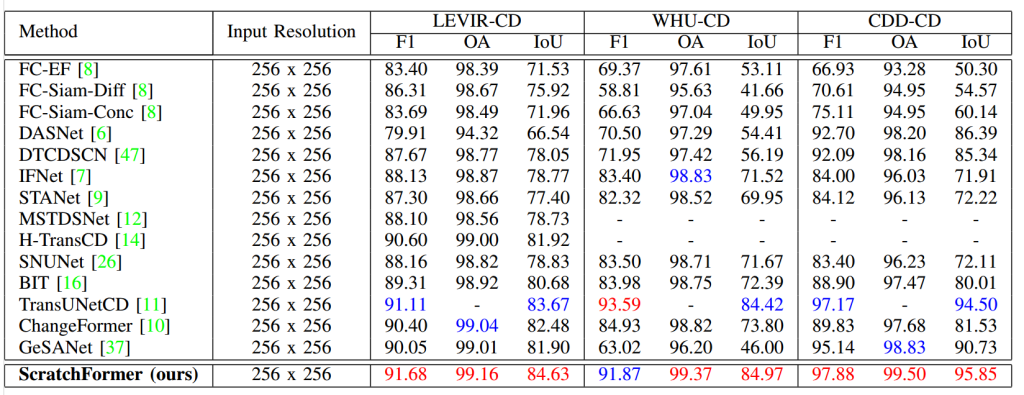
表 1 LEVIR-CD、WHU-CD 和 CDD-CD 数据集上的最先进方法对比。本文报告了 F1、IoU 和 OA 指标的结果。ScratchFormer 显著优于现有方法,实现了最先进的性能。最佳两个结果分别用红色和蓝色表示。

表 2 LEVIR-CD 数据集上基于 Transformer 骨干网络的方法在参数、单图像对推理时间和每轮训练时间方面的对比。
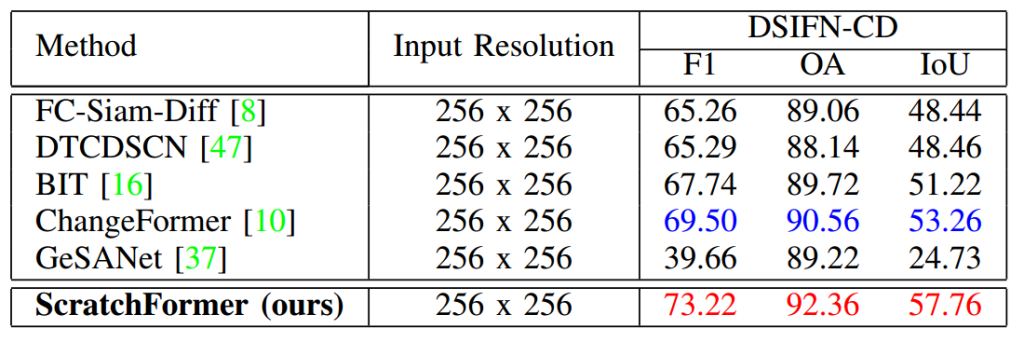
表 3 DSIFN-CD 数据集上的最先进方法对比,包括 F1、IoU 和 OA 指标。为了公平对比,本文基于最先进方法的公开代码报告结果。ScratchFormer 显著优于现有方法,实现了最先进的性能。最佳两个结果分别用红色和蓝色表示。
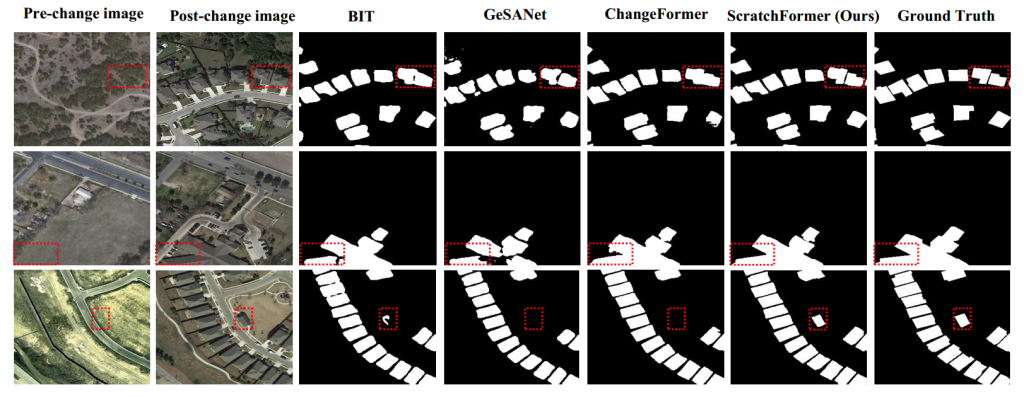
图 6 LEVIR-CD 数据集上的定性对比。将所提 ScratchFormer 与 BIT、GeSANet 和 ChangeFormer 进行对比。与现有方法相比,所提 ScratchFormer 通过精确检测正确的变化(红色框标记),边界清晰,实现了更优的变化检测性能。
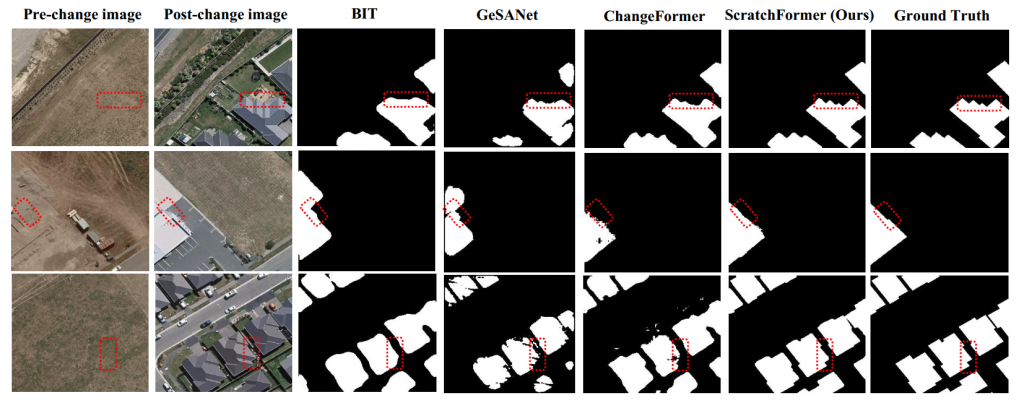
图 7 WHU-CD 数据集上的定性对比。将所提 ScratchFormer 与 BIT、GeSANet 和 ChangeFormer 进行对比。值得注意的是,所提 ScratchFormer 通过精确检测语义变化,边界清晰(红色框标记),实现了更优的变化检测性能。

图 8 CDD-CD 数据集上的定性对比。可以看出,所提 ScratchFormer 能够更好地检测变化前和变化后图像之间的语义变化,边界清晰。

图 9 DSIFN-CD 数据集上的定性对比。将所提 ScratchFormer 与 BIT、GeSANet 和 ChangeFormer 进行对比。与其他方法相比,所提 ScratchFormer 能够更好地检测语义变化(红色框标记),变化前和变化后图像之间的边界清晰。
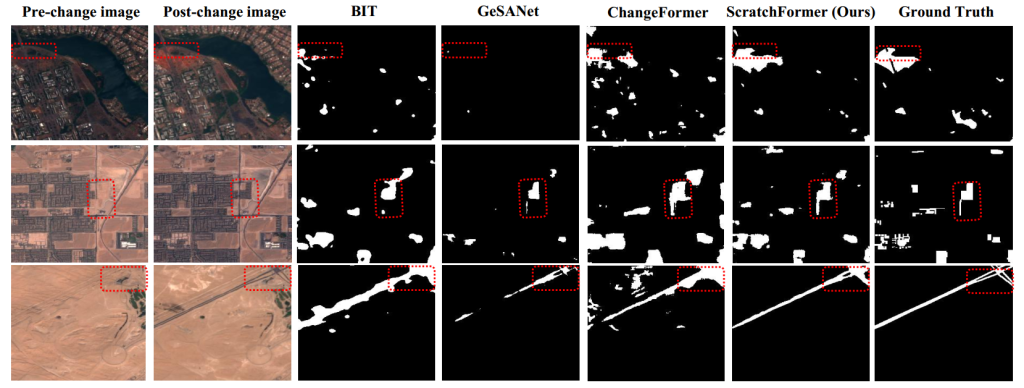
图 10 OSCD 数据集上的定性对比。可以看出,所提 ScratchFormer 能够更好地检测变化前和变化后图像之间的语义变化,边界清晰(红色框标记)。
5.3 消融试验


翻译
本文在 LEVIR-CD 数据集上进行消融实验,以验证所提创新的有效性。表 4 展示了基线对比结果。基线方法(第三节 A 部分)通过随机初始化从零训练,在 LEVIR-CD 数据集上的 IoU 分数为 82.53%(第 4 行)。当首先在 DSIFN-CD 数据集上预训练基线方法,然后在 LEVIR-CD(目标)数据集上微调时,基线方法的结果提升至 82.89%(第 3 行)。当将所提 SSA 层(第四节 C 部分)集成到基线方法中时,IoU 分数提升至 83.62%(第 5 行)。所提最终 ScratchFormer 包含两种创新(SSA 和 CEFF),通过从零训练,性能显著提升,IoU 分数达到 84.63%。这些结果证明了所提创新的有效性。除了基线对比外,本文还报告了 ChangeFormer 在预训练和从零训练情况下的结果。与 ChangeFormer 相比,所提 ScratchFormer 在所有三个指标上均实现了持续提升。
本文进一步进行实验,将所提 CEFF 模块与基于标准求和、差分和拼接的技术进行对比。其中,对\(\hat{F}_{pre}^i\)和\(\hat{F}_{post}^i\)执行求和、差分和拼接操作,然后输入到两个卷积层中。表 7 展示了对比结果。与这些技术相比,利用特征通道重加权的所提 CEFF 实现了更优的性能。
打乱稀疏特征:偏移量的预测计算方法改编自可变形卷积网络 [45]。所提方法采用稀疏子采样,而非密集子采样。实验结果表明,与利用计算得到的偏移量对打乱位置进行密集子采样相比,所提方法实现了更优的性能(所提方法:84.63% vs. 密集子采样:LEVIR-CD 数据集上 IoU 分数为 83.37%)。本文进一步推测,这一提升可能是由于通过关注遥感变化检测图像中的稀疏信息区域,有效学习了丰富的特征表示。相比之下,对均匀采样的密集块进行密集子采样,可能难以学习丰富的特征表示,因为遥感场景中存在稀疏信息区域,这些区域中的物体形状多样且外观不一致。
稀疏因子:本文还通过改变稀疏因子\(\gamma\)(2、4 和 8)进行实验,以确定所提 SSA 的最优稀疏度,如表 6 所示。实验结果表明,对于 LEVIR-CD 数据集,\(\gamma=4\)时实现了最优性能。因此,本文固定\(\gamma\)的值,并在所有实验中采用相同的值。
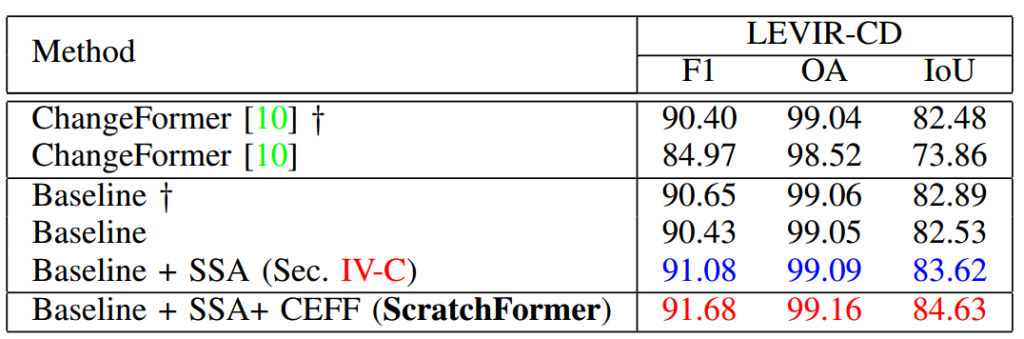
表 4 LEVIR-CD 数据集上的消融实验。本文展示了将所提创新集成到基线方法中的效果。†表示模型首先在其他变化检测数据集上预训练,然后在目标变化检测数据集上微调。将所提 SSA(第 5 行)集成到基线方法(第 4 行)中,性能持续提升。所提最终方法 ScratchFormer(第 6 行)包含 SSA 和 CEFF,与基线方法相比,性能显著提升。本文还报告了 ChangeFormer 在预训练和从零训练情况下的结果。最佳两个结果分别用红色和蓝色表示。
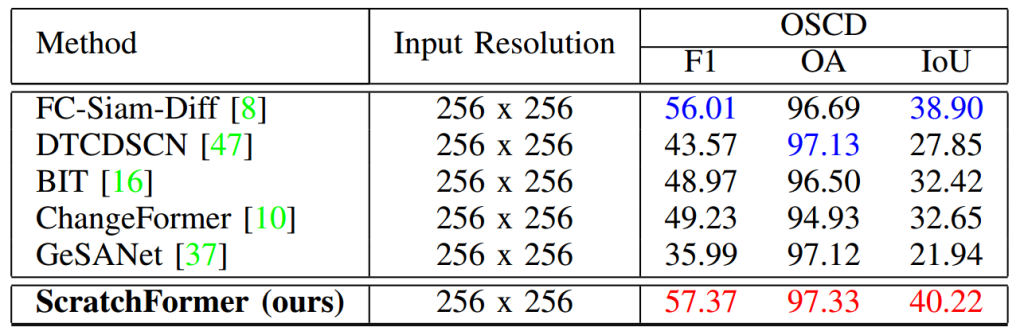
表 5 OSCD 数据集上的最先进方法对比。为了公平对比,本文报告了 F1、IoU 和 OA 指标的结果。ScratchFormer 显著优于现有方法,实现了最先进的性能。最佳两个结果分别用红色和蓝色表示。

表 6 LEVIR-CD 数据集上稀疏因子γ的对比。γ=4时实现了更优的性能。最佳结果用粗体表示。
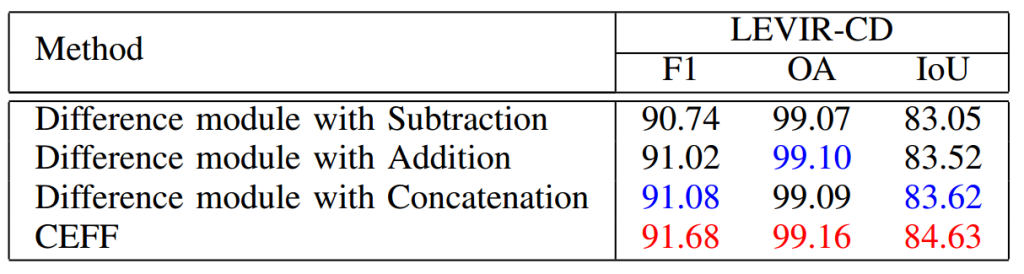
表 7 LEVIR-CD 数据集上 CEFF 与基于差分、求和和拼接的技术的对比。CEFF 在所有指标上均实现了更优的性能。最佳两个结果分别用红色和蓝色表示。
6 结论
翻译
本文提出一种基于 Transformer 的孪生架构 ScratchFormer,用于遥感变化检测问题。所提 ScratchFormer 引入打乱稀疏注意力,以便从零训练时有效捕捉固有特征。本文进一步引入变化增强特征融合模块,通过逐通道特征加权,增强相关语义变化,同时抑制噪声变化。本文通过在多个常用变化检测基准数据集上进行大量实验,验证了所提方法的有效性,这些数据集具有不同的挑战。例如,LEVIR-CD 和 WHU-CD 数据集面临不同的挑战,如建筑物阴影、颜色变化、植被变化以及各种形状和尺寸不规则的建筑物;而 CDD-CD 数据集面临边界精确划分的挑战,这可能是由于多种因素造成的,包括图像分辨率、传感器限制以及季节性变化图像采集导致的变化特性。所提方法在所有这些数据集上的性能均优于现有变化检测方法。未来的研究方向包括进一步探索季节性变化图像场景中的精确边界划分,以及基于 Transformer 的遥感变化检测在省级尺度的泛化性 [48,49]。另一个未来研究方向是探索自然图像和医学图像中的变化检测问题。
模型训练情况
tools文件夹下有模型训练的入口py文件train.py与模型测试的入口test.py
命令行输入:
python tools/train.py configs/..... --work-dir outpus/dir_name # 训练模型代码
python tools/test.py configs/..... (训练的checkpoint路径) --work-dir result_outpus/dir_nameconfigs文件夹下的都是骨干模型(我猜的)
先是跑的服务器上open-cd里的模型,
2025.11.29从上午10点训练到晚上21:30左右,仅训练了70轮,地下室关门将电脑关机了。
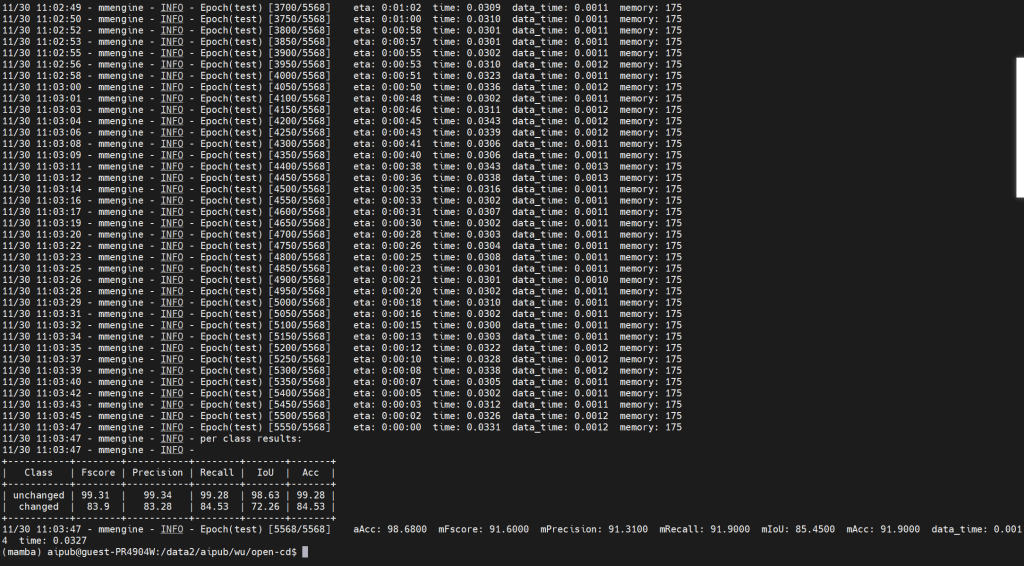
本次使用WHU数据集训练,输入到模型中的尺寸为256×256,在WHU验证集上的结果:
在训练最高轮数70的验证情况
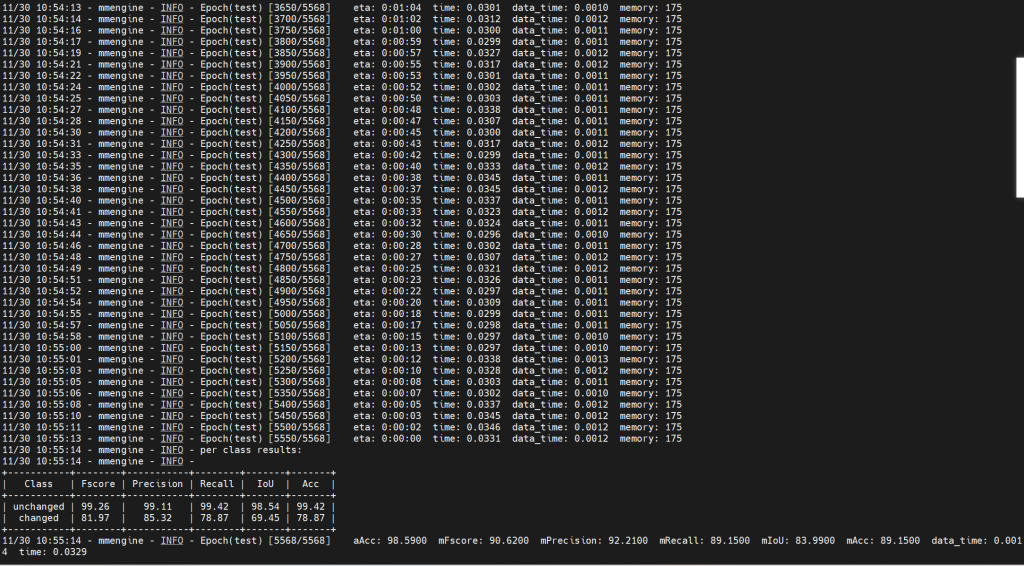
在保存最优IoU的轮数(20)的验证情况
nohup关键字,该命令在服务器上使用,即使连接服务器的电脑掉线,也能保持后台训练,具体命令行:
nohup python tools/test.py configs/rwkvcd/rwkv_b_256x256_40k_levircd.py outputs/WHU_train_epoch100_anyone/best_mIoU_epoch_100.pth --work-dir result_outputs/anyone_val_whu/max_best_epoch100 > train_logs_nohup 2>&1 &主要结构:
nohup python 训练入口py文件 (配置文件路径,比如configs/..py) (文件输出路径,比如--work-dir outputs/...) > 训练日志文件.log路径(即训练过程打印的各种信息) 2>&1 &